【cg】RTX光线追踪与DDGI
前言
DDGI(Dynamic Diffuse Global Illumination,动态漫反射全局光照)[1]是由Nvidia于2019年推出的基于光线追踪(Ray Tracing)的一种动态漫反射全局光照方案。
该方案基于Nvidia的RTX(Ray Tracing X)[2]标准和微软的DXR(DirectX Raytracing) API,本文所讲的是此方案基于在ue中的实现。
我们接下来将会领略一下这套方案的风采,窥探一下其中的某些细节,并沿途购买一些周边扩展知识。
本文将会分两次介绍光线追踪部分,第一次会介绍一下实现DDGI最基础流程所必须的一些概念和实现。第二次会在我们十分熟悉DDGI之后再进一步了解一下光追管线是如何与材质、着色等结合在一起,并最终得到一个相对完整的渲染流程拼图的过程。
啥是全局光照
在开始之前,显然我们要考虑的首要问题就是"啥是全局光照?"。

在不考虑红绿色盲的情况,之所以我们看到红色的物体是红色的,绿色的物体是绿色的,是因为光线经过物体表面后,只反弹(bounce)出了与其颜色波长相同的光波。


在图形渲染领域,我们将这种只经过一次光线反弹(bounce)得到颜色结果的过程称为直接光照(direct lighting),如(图2-2)所示。而且计算这个颜色结果的方法也有很多,不同的方法得到的结果也各不相同,这些方法被称为光照模型(lighting mode),此处暂且按下不表。
但是光线并不会只反弹一次,在第一次反弹之后,很有可能再次反弹到另一个物体表面上,而非直接弹入人眼。
这种经过非第一次反弹之后才传入人眼的光照被称为间接光照(indirect lighting),如(图2-3)所示。在图形渲染领域,我们通常只关注和重点计算犀利性价比最高的第二次反弹的间接光照。

对于一个物体表面来说,它可能会接收来自四面八方的其他表面二次反弹过来的光线,如(图2-4)所示。这些光线的波长受到了上一个表面的颜色信息的影响,所以计算某一表面的间接光时,需要整个场景中其他物体表面的光照信息。
从这一点来看,称之为全局光照,仿佛容易理解了。正规地说,全局光照应该是叠加了所有直接光照和间接光照结果的场景光照结果。但我们在日常生活中说计算全局光照时,一般是指计算二次反弹的间接光照而已,本文后续所提到的全局光照也为此意。
计算全局光照的方法多种多样,一言难尽。这里仅从一些总结性方向上作必要的简单介绍,读者可另行补充各种方案的细节,后续作者也会发布一篇对各种方案总结提炼的详细博客,以作为本人探索全局光照的总纲。
我们基本上可以将全局光照方案大致分为离线和实时两大类。
Baked GI
如下表所示,其中离线方案的代表有经典的基于烘焙Lightmap的方案。其中最具代表性的是基于烘焙unreal的Lightmass,它采用光子映射的方法为场景的每个像素烘焙间接光。除此之外,它还支持离线烘焙额外Probe的方案,即ILC和VLM,以更好地使动态物体也受烘焙的间接光影响。其中ILC会在场景中静态物体表面生成一些probe,并对同一个物体应用同一份probe数据。而VLM会生成范围更广的probe,且逐像素应用于物体表面,比ILC精度更高。



除此之外,还有一种基于PRT的烘焙方式,采用Split Sum的方式逐顶点分别预处理光源项和传输项,并使用正交基函数编码到各顶点数据中用于shader计算。
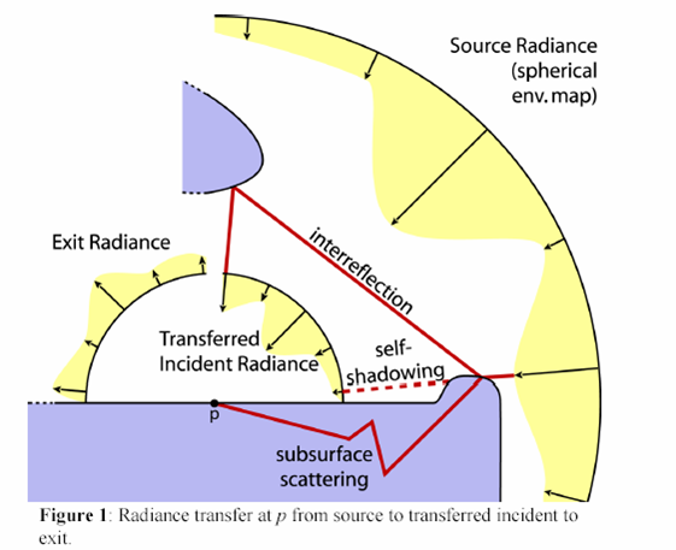
它们的优点是烘焙精度高,结果细腻,缺点也很明显,工作流程长,包体占用大,无法处理动态场景或动态光源。
Lightmass(Lightmass)
ILC(indirect light cache)
VLM(volumetric lightmap)
PRT(precomputed radiance transfer)
VPL
而实时方案也比较多。如下表所示一类基于VPL(virtual point lights)的方案,这类方案的特点是用各种方法在场景中某些位置创建虚拟的点光源,该点光源的强度来自一次反弹,所以受这些点光源影响的表面接受的便是二次反弹了,从而近似地计算出了间接光。
VPL是一类处理方案,它始发于97年的instance radiosity,该方案从光源方向随机投射光线,当其与场景物体表面相交时生成虚拟点光源,该点光源的出射光强度来自该直接光源。当真正对物体表面着色时,将计算所有虚拟点光源对其的光照影响,从而模拟二次反弹。
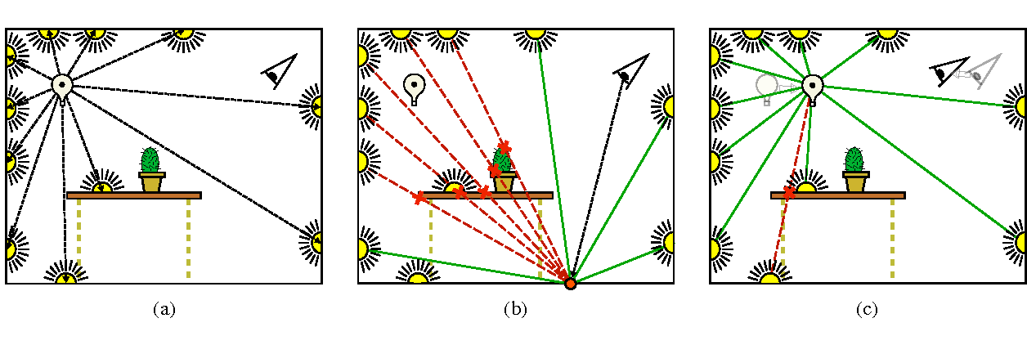
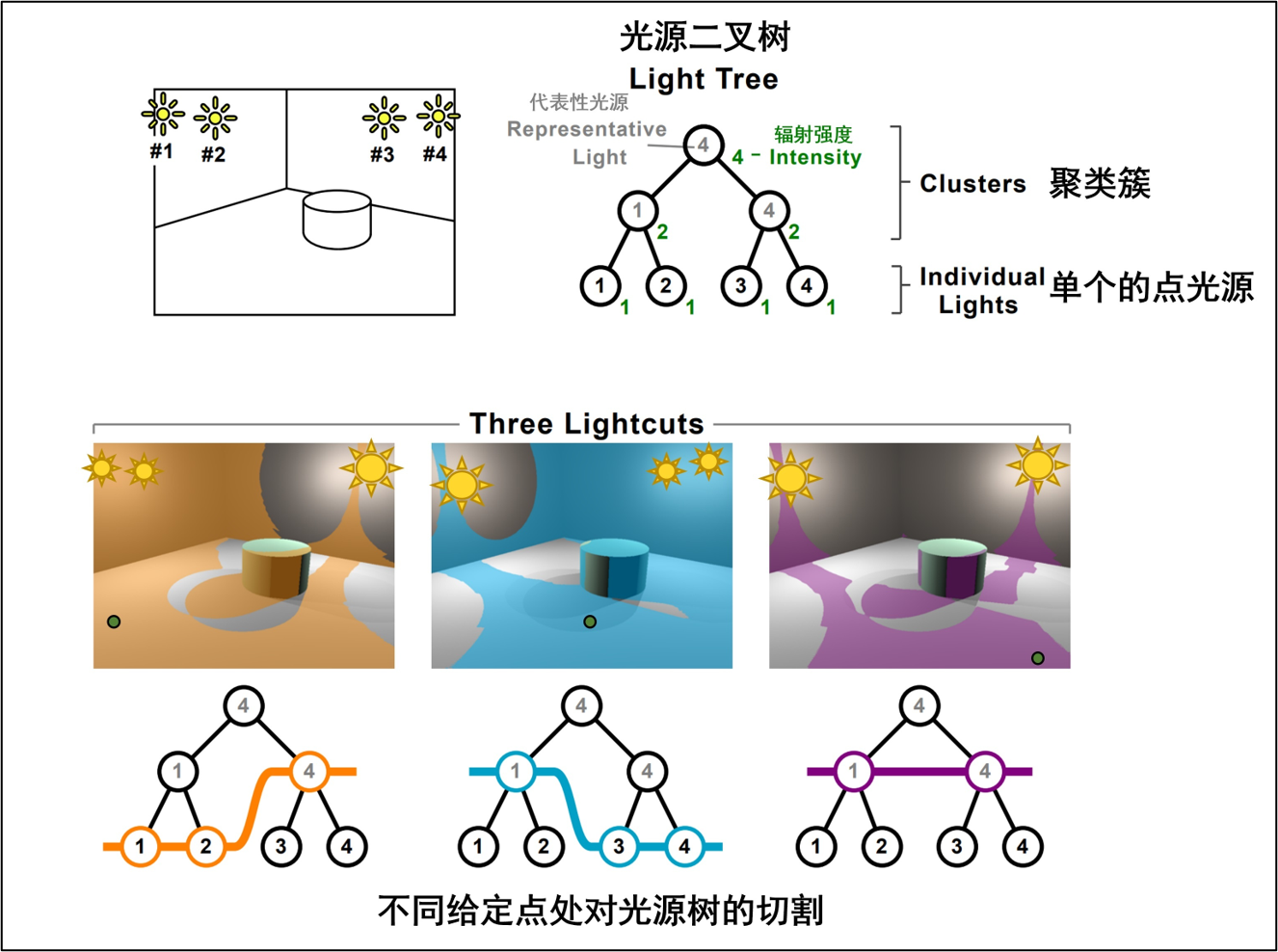
该方案将复杂的递归光线追踪过程近似为大量虚拟点光的直接光照这一相对简单的问题,并由此产生了一系列的多光绘制算法(many-lights rendering),如light cut,它将vpl使用层次化结构管理起来,形成表征光源。
除此之外,还有一种叫做RSM(reflective shadow map)的方案,它利用光源空间(lightspace)的shadow map gbuffer生成vpl。更进一步还有LPV(light propagation volumn),它将RSM生成的vpl注入到一张3d volume中并向相邻网格增殖出更多的vpl。


但是不少vpl方案都有可见性计算的问题,如RSM并没有考虑虚拟点光与物体之间的可见性,所以生成的间接光是没有考虑阴影的。一般可以通过在应用vpl时通过ray marching之类的屏幕空间算法来计算可见性,但性能消耗就上去了。还有一种方案是ISM(imperfect shadow map),该方案为vpl选择离散的点来近似计算可见性。

IR(instant radiosity)
RSM(reflective shadow map)
LPV(light propagation volumn)
ISM(imperfect shadow map)
Light Cut
Scene Space GI
如下表所示,有一些基于屏幕空间的GI方案。其中ssgi也是基于VPL的。
SSGI也是基于屏幕空间进行raymarching,它在像素附近半径内找采样点进行raymarching,碰到相交的表面即为vpl,所以它也可以说是一种vpl的方案。
SSDO在屏幕空间不做raymarching,而是通过找附近半径内随机采样点并与深度值进行对比,从而筛选出vpl。相当于view到采样点方向的一个"一步到位"的raymarching。
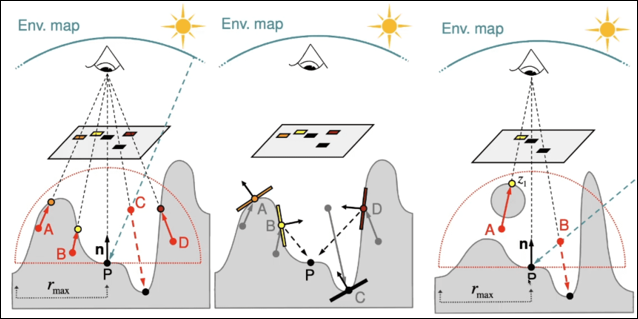
SSGI(screen space global illumination)
SSDO(screen space directional occlusion)
Voxel GI
还有一些体素化的方案,如SVOGI(sparse voxel octree GI)、VXGI (voxel GI)等。这类方案将场景稀疏体素化之后,使用“Voxel Cone Tracing”体素锥体追踪的方法收敛间接光,类似于体积光的收敛过程。
其中SVOGI将八叉树存储在一张邻接2D Texture上,而VXGI则存储在clipmap上。
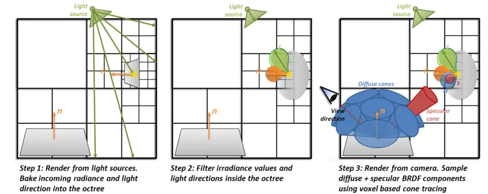
SVOGI (sparse voxel octree GI)
VXGI (voxel GI)
Probe GI
还有一类很重要的基于Probe的方案。
如Probe-based PRT。前面烘焙的prt是逐顶点烘焙的,但是这种烘焙方式效果比较低,且需要额外的顶点数据。有一种基于Probe的PRT方案优化了这个问题。该方案在场景中按照一定规则摆放probe,作为物体表面着色的代表。我们一般会计算所有Probe上的光照信息,并在最终着色时采样某个物体表面周围的probe作为间接光。前文提到的ILC和VLM其实也是一种基于probe的方案,只不过它是作为Lightmass的一种补偿。

而本文的主角,DDGI(dynamic diffuse global illumination)也是一种基于Probe的方案,话休絮繁,我们后文再作拆解。

DDGI(dynamic diffuse global illumination)
Probe-based PRT
Other Newly GI
除此之外,还有一些更复杂、更完整、或者更先进的新世纪方案。
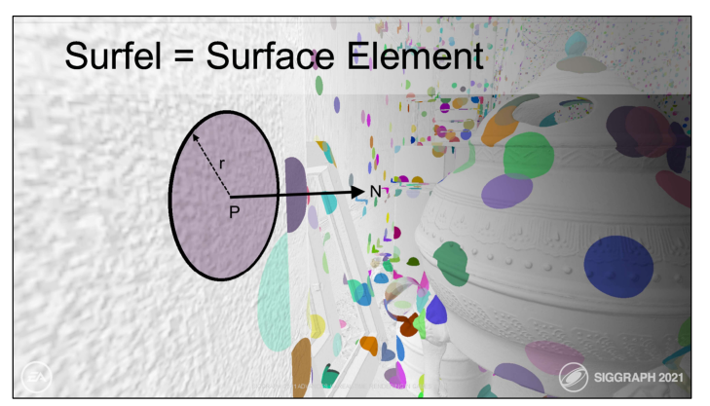
如Surfel GI。这个方案在屏幕空间生成以surfel(半径与法线组成的面片)为元素的表面代理,并持久化存储。
如Lumen。它是一个集光线追踪、表面缓存、ss radiance cache、voxel gi、ssgi、ss probe、sdf等技术于一体的综合性gi方案。

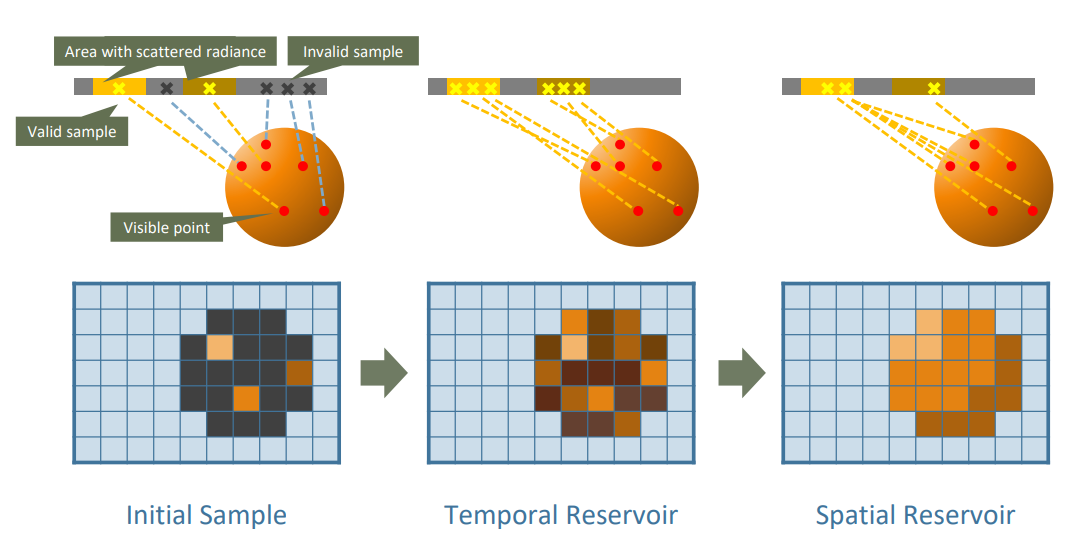
当然还有一些是在RTX光线追踪框架下的新型方案。如ReSTIR GI[3],它是Nvidia于2020年发表的ReSTIR(Reservoir-based Spatio Temporal Importance Resampling),即基于储层的时空重要性采样在GI上的应用,它在求交能力之上又更进一步告诉了用户如何更高效地选择投射光线的方向及复用投射路径等信息的方法。
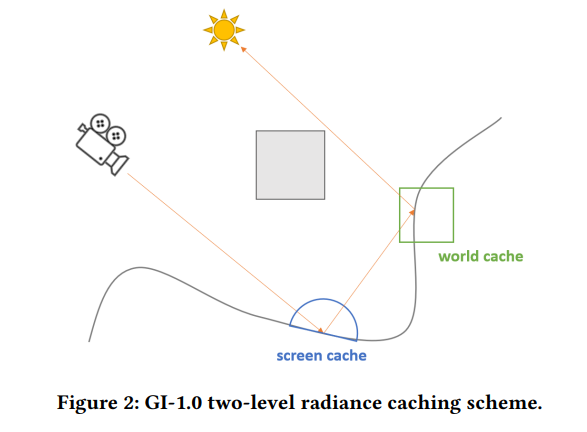
如AMD的GI-1.0[4],它是基于Two-Level Radiance Caching的一个方案,同时结合了ReSTIR部分思想和原理,可以看作Lumen的进阶版。
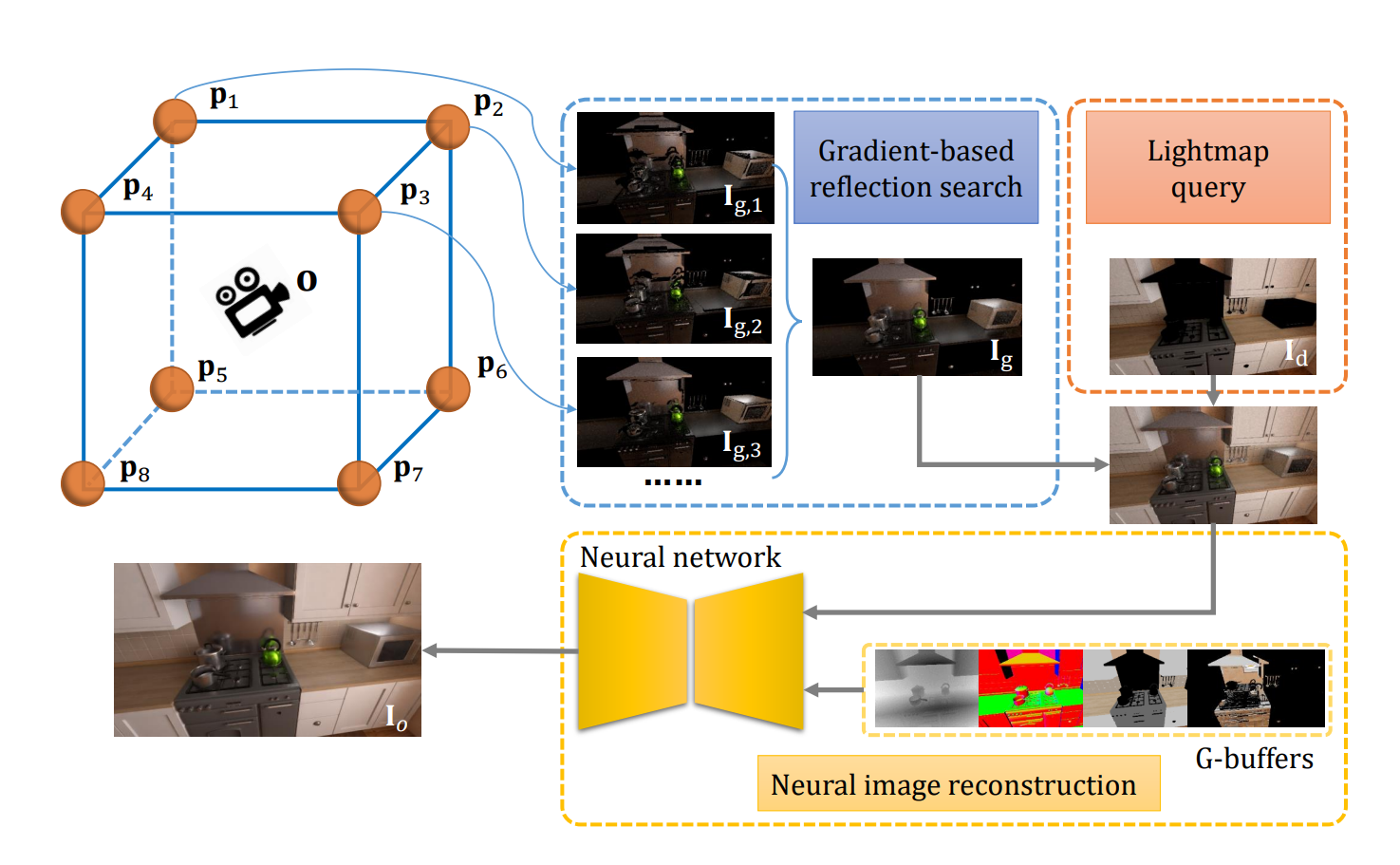
如NN Probe GI(neural network based GI)[5] (暂且这么叫它得了),这是一种利用神经网络快速收敛probe的新型方案。
Surfel GI
Lumen
AMD GI-1.0
ReSTIR GI
NN Probe GI(neural network based GI)
此处介绍这么多,也只是为了让大家了解对GI世界有一个整体的世界观,以便认清DDGI在这个GI世界中的尴尬处境。
啥是光线追踪
正文开始!
我们首先来了解一下实现相对完整的DDGI上层流程所需要用到的光线追踪(ray tracing)相关知识点。
对于传统的光栅化流程来说,我们所看到的显示器屏幕上每个像素呈现的颜色,是由各个模型顶点经过光栅化之后得到每个像素的数据,然后进行着色计算得出的,然而这里的着色过程一般只有部分光源与当前着色点的信息,并不会充分考虑整个场景的物体分布和光线的传输方式,所以得到的结果与物理世界的真实情况一般会有比较大的差距。
而光线追踪则与光栅化完全不同的流程得到像素颜色的,它一般是从相机出发,对于每个像素点,都向场景投射一定数量的光线,直到光线与场景中物体表面相交,然后才在交点处根据物体材质和光照模型等进行着色。这个过程中也会在交点处根据材质决定光线发生反射或折射,继续进一步多次投射反射光线和折射光线,直到光线与下一个表面相交,直到光线到达光源或逸出场景。
所以整个着色过程充分考虑了场景的物体分布以及光线的传输方式,与物理世界的实际情况比较类似。
从一个更宏观的角度来说,光线追踪并不只是追求完成某个像素的计算流程这一单一的需求。它更多地代表着一种能力,即场景与光线求交的能力。这种能力可以解决对前面各种GI方案大多数来说都比较棘手的可见性问题,有些方案甚至非常不要脸地直接忽略了可见性计算(这很图形学)。
这种能力使得我们在GPU上也可以获得相对完整的场景描述,并且并行地与大量光线进行交互。这与传统的光栅化流程比有了额外的数据,自然也有了更准确的结果。
这种能力也并非只能用来替代光栅化,我们完全可以利用它去做额外的流程来从而计算出额外的结果,比如这里的DDGI,或者基本光追的阴影、AO等。
我们会在文章结尾初步了解光线追踪和DDGI之后,再回过头来讨论一下关于光线追踪作为一种能力而非流程的问题。
RTX光线追踪
我们这里以现代硬件光追为讨论对象,传统的cpu软光追,或者厂商自己使用ps实现的魔改版光追不在我们的范围内。

谈到现代光线追踪,总会有几个主要角色登场,如Nvidia、Microsoft、Epic等。那么他们在这场光追盛宴中具体担任什么角色,我们需要理清楚一下。
| 概念 | 厂商 | 年份 | 角色 |
|---|---|---|---|
| RTX(Ray Tracing X) | Nvidia | 2018 | Standard |
| DXR(DirectX Raytracing) | Microsoft | 2018 | API |
| Ray Tracing RHI for DXR | Epic | 2019 | RHI |
| Vulkan RTX API | Khronos Group | 2020 | API |
Nvidia在2018年推出了RTX(Ray Tracing X)标准。同时期微软配合实现了符合该标准的API,即DXR(DirectX Raytracing),至此光线追踪可使用这套API运行于支持该标准的显卡上。
2019年,Epic将DXR相关API封装进UnrealEngine,实现了相对完整的DXR管线。本文所分析的DDGI就是以这个环境下的实现为例。
2020年,Khronos后来居上,也在vulkan上实现了一套符合RTX标准的API,使得使用vulkan api实现光线追踪成为可能。
核心流程与全新着色器
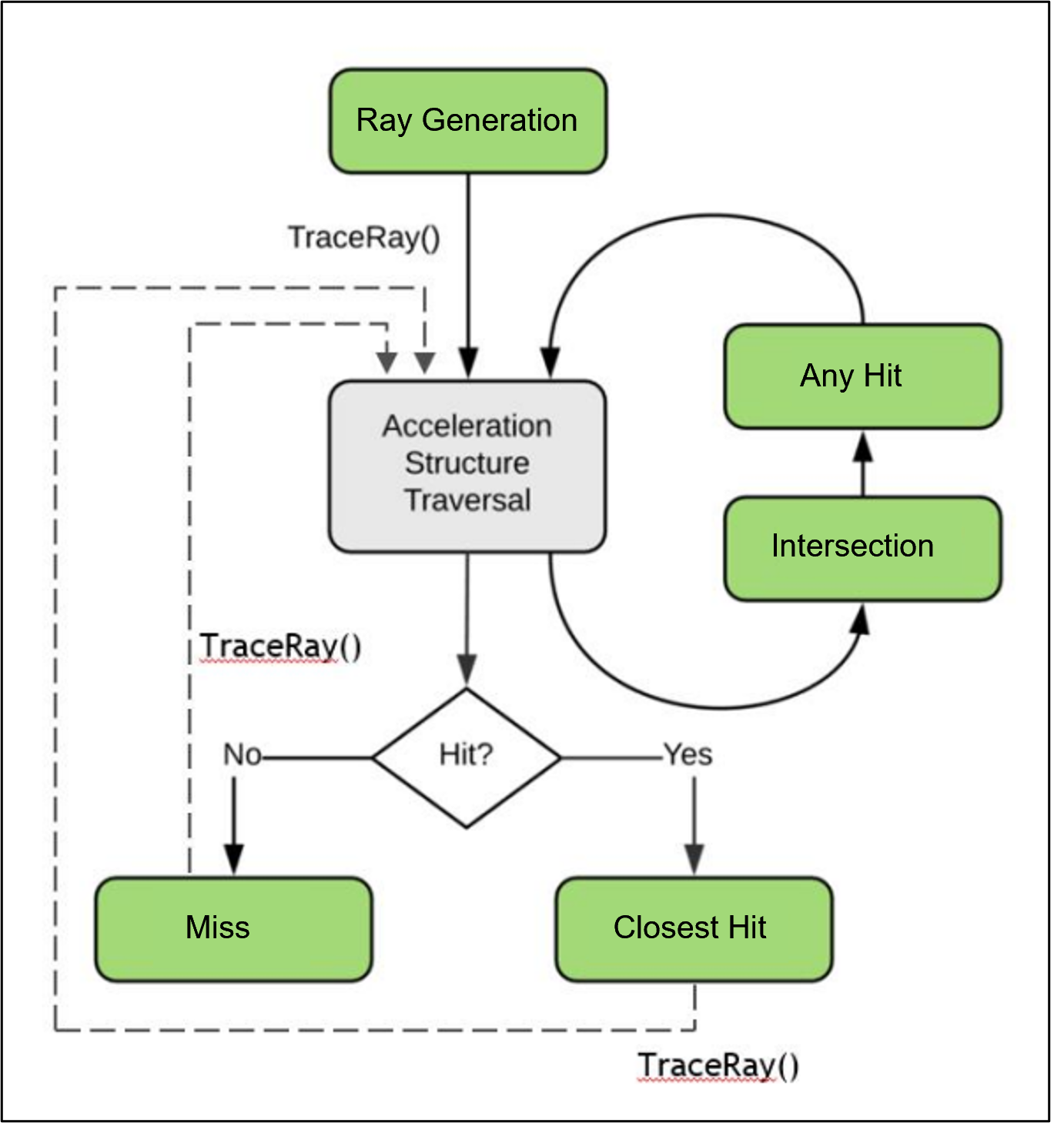
RTX光追的核心流程大致如图所示。
在这个流程中,我们会将场景信息存储为加速结构(Acceleration Structure, AS),并使GPU也可访问这部分数据。这里我们可以认为是一份GPU上可以描述场景信息的数据,具体细节暂且不表。
然后通过向场景(加速结构)中投射光线,并不断与场景(加速结构)求交,并根据求交情况触发不同的结果。
这里只简单介绍后面实现DDGI时涉及到的一小部分实现,具体更详细的管线状态绑定、TLAS的创建、ShaderTable的收集等工作,在后面的扩展章节会更广泛地讨论一下。
如上图所示,若想了解在GPU上并行执行RTX光追的过程,首先需要了解这里新增的5种着色器类型,即
RGS(Ray Generation Shader)。用于发射光线。必须的。
IS(Intersection Shader)。用于自定义加速结构基元的求交规则。可选的。
AHS(Any Hit Shader)。射线与加速结构有任一交点时被触发。可选的。
CHS(Closest Hit Shader)。最近的有效交点才触发,每条射线最多触发一次。可选的。
MS(Miss Shader)。光线没有与场景中的任何基元相交时触发。必须的。
RGS(Ray Generation Shader)主要用来发射光线。它通过关键字raygeneration标识shader。

它通过新的dxR API TraceRay()来发射光线,如下图所示。
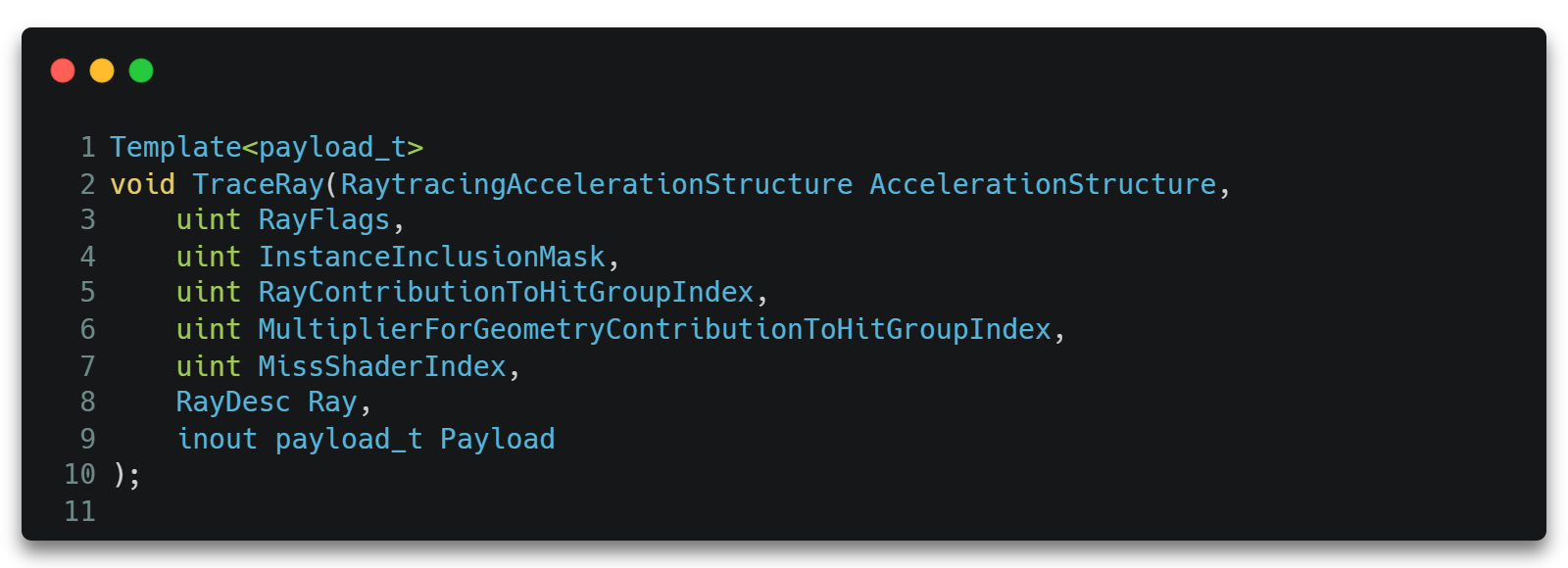
其中各参数的变量含义如下所示。
- AccelerationStructure。要使用的加速结构。我们会在扩展章节再展开。
- RayFlags。光线标志的组合。它可以控制当前这条光线求交时的表现,此处也按下不表。
- InstanceInclusionMask。加速结构中几何体的Mask。可以使当前光线过滤掉加速结构中打了某些Mask的几何体。此处也按下不表。
- RayContributionToHitGroupIndex。可以理解为光线的类型索引,用于后续根据不同的光线的类型选择不同的Hit Group。此处也按下不表。
- MultiplierForGeometryContributionToShaderIndex。可以理解为光线类型的总数。此处也按下不表。
- MissShaderIndex。MS类型的总数,一般跟光源的类型数量有关。此处也按下不表。
- Ray。当前发射的光线属性。我们将在分析DDGI的过程中逐渐熟悉它。
- Payload。 用户自定义的回溯数据,用于在递归发射光线的流程中存储需要回溯回来的数据。我们也会在后续的过程中逐渐熟悉它。
一般Payload数据会最终回溯到调用TraceRay()的地方,如这里的RGS里,一个最简单的RGS实现如下。
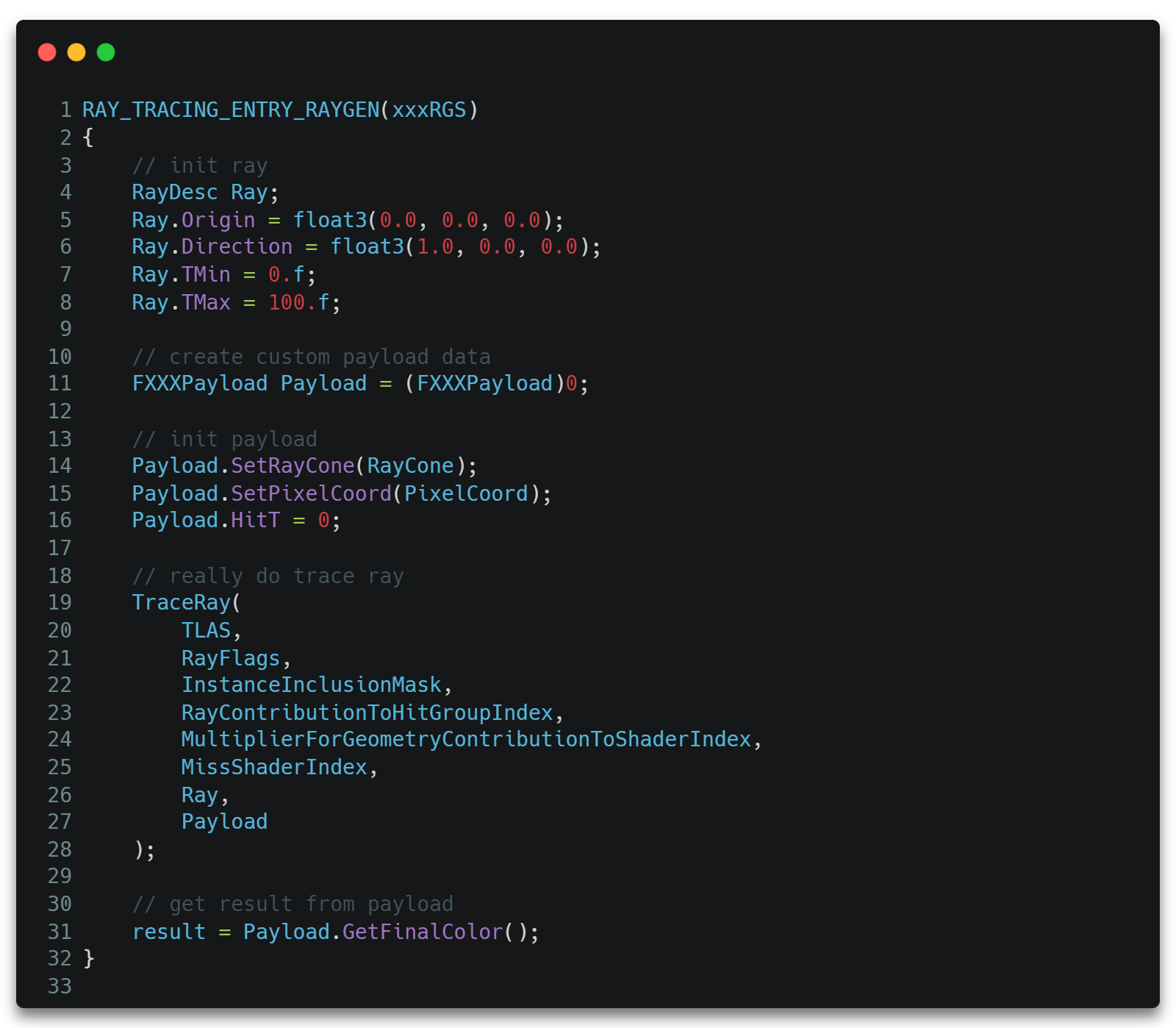
除此之外,RTX光追流程的发起也是通过dxR APIDispatchRays()启动,在GPU上多个线程上并行地发射光线,所以只要指定光线的数量即可发起。
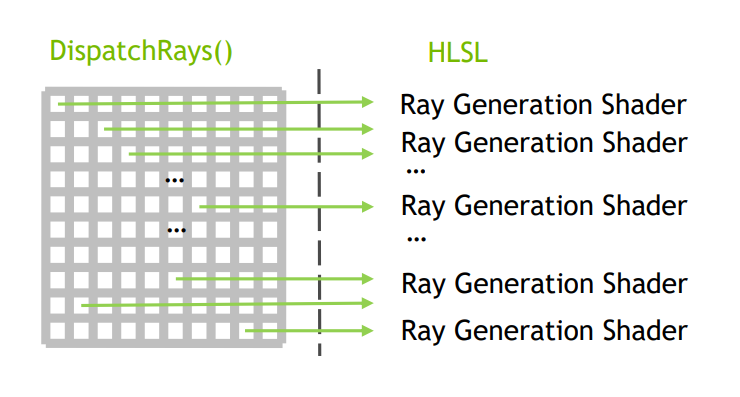

当光线发射之后,便开始遍历加速结构中的每一个节点,其叶子节点为几何体基元的AABB包围盒,这一过程叫做Traversal。
对于每一个遍历到的叶子节点,都会执行相交测试,即Intersection,从而决定该光线是否与当前节点中的基元相交并记录或更新交点属性。直到遍历尽节点或者在某些特殊的条件(后文会谈到)下会终止遍历循环。
它通过关键字intersection标识shader。

在IS[6]中,我们将定制光线与基元的求交算法,并通过dxR API ReportHit()[7]上报求交情况。
1 | template<attr_t> |
其中THit是当前交点的信息,它可唯一确定光线上一点。HitKind是一个自定义的枚举,按下不表。Attributes是用户自定义的数据,也先按下不表。
其返回值由后面执行的Any Hit Shader确定,我们将在AHS页签谈及。
之所以需要IS,是因为除了默认的三角形作为基元外,加速结构其实是允许我们自定义基元类型的,而IS就是为了解决用户自定义的基元与光线的求交算法,一个简略的IS代码如下。
1 | struct CustomPrimitiveDef { ... }; |
而默认的情况下,即加速结构中的基元是三角形面片的情况下,是不需要我们自定义IS的,即IS可以是缺省的,此时Attributes参数将使用默认Fixed-function triangle intersection结构体[8],即只存储了三角形基元重心坐标的结构体。
1 | struct BuiltInTriangleIntersectionAttributes |
事实上,ReportHit()是一个可以挂起/激活的长生命周期函数,它有着与AHS紧密关联的更复杂些的流程,此处暂且按下不表。
当IS阶段产生了有效的交点之后,如果该交点是不透明的(opaque),则会直接上报交点。但如果交点是半透明的,那么将会触发执行Any Hit Shader。
AHS将会决定如何处置当前的交点,如接受并上报该交点,或者直接忽略掉该交点等。它通过关键字anyhit标识shader。
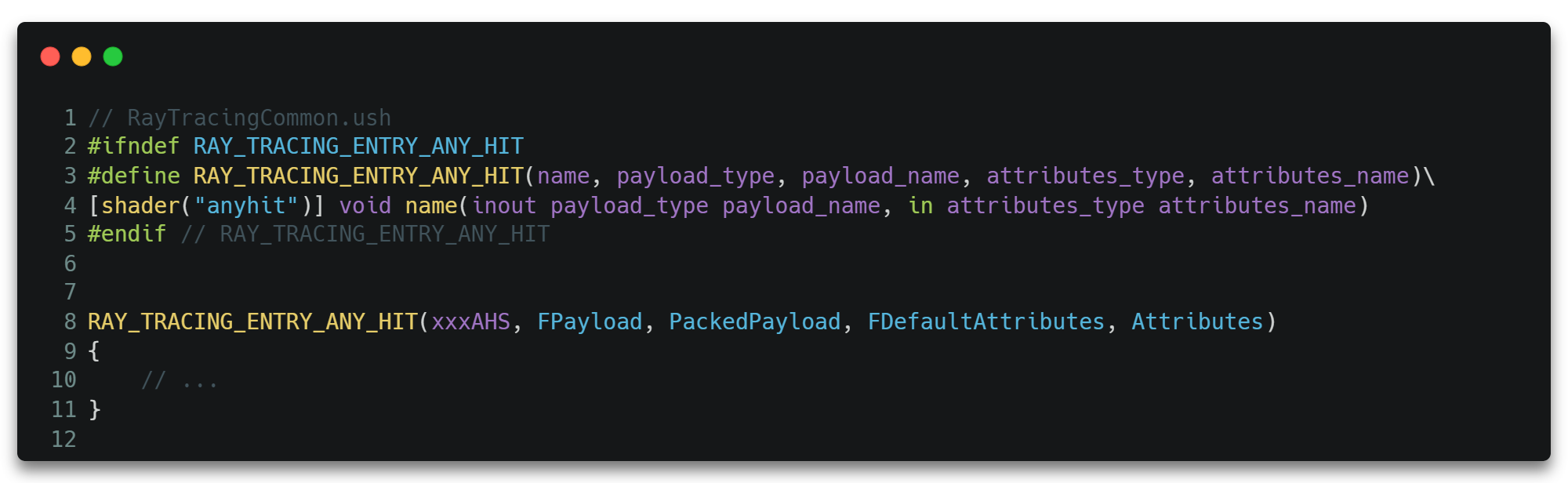
可以看到,AHS的入口函数带有两个参数,而这两个参数的类型竟然是我们在RGS和IS里都见过的。其实Payload参数确实来自RGS的TraceRay()传入的参数,而Attributes则来自IS的ReportHit()传入的参数。事实上,正是TraceRay()的调用,才触发了后续的IS的执行,也正是IS中ReportHit()的调用,才触发了后续AHS的执行。
但是特殊的是,ReportHit()也是一个回调函数,它将暂时挂起IS并等待AHS返回结果之后才有可能继续执行IS。
而AHS的返回情况大概有三种。
- 调用了dxR API
IgnoreHit()。此时ReportHit()会返回false,IS激活后会执行false相关分支。
- 调用了dxR API
AcceptHitAndEndSearch()。此时将会直接上报当前交点,并放弃当前遍历加速结构节点的循环流程,也不会再次激活之前挂起的IS了。
- 上面两个API都没有调用。此时
ReportHit()会返回true,IS激活后会执行true相关分支。
一个示例代码如下所示。
1 | RAY_TRACING_ENTRY_ANY_HIT(TestAHS, FDefaultPayload, Payload, FDefaultAttributes, Attributes) |
注,这里虽然大致解释了IS与AHS的核心联系,但其实也暂时避开了一些细节,在后面的章节会有更详细的展开和总结。
当遍历完加速结构中跟当前光线相关的所有节点或者在某些特殊的条件(如AHS里提前EndSearch等)下会终止Traversal和Intersection循环。从而进入下一阶段。
如果在之前的Traversal和Intersection过程中有上报过交点,那么将会走进Closest Hit Shader,在此shader中可读取当前光线最终确定的最近交点的属性,并执行一些其他操作,如将当前交点处的材质信息存入Payload等。
它通过关键字closesthit标识shader。

除此之外,CHS对于每一个光线最多只会执行一次。它也有能力再次调用TraceRay()发射新的光线出去,从而模拟递归地多次反弹光线。一个简单的示例如下。
1 | RAY_TRACING_ENTRY_CLOSEST_HIT(TestCHS, FDefaultPayload, Payload, FDefaultAttributes, Attributes) |
如果在之前的Traversal和Intersection过程中没有上报过交点,那么将会走进Miss Shader,表示当前光线与场景并没有任何交点,且该光线很有可能打到某个光源方向上。
一般来说,不同的光源由于光照模型计算方式不同,光源参数也不同,所以会使用不同的MS。所以真正的光照计算也大多在MS中进行。
它使用关键字miss标识shader。
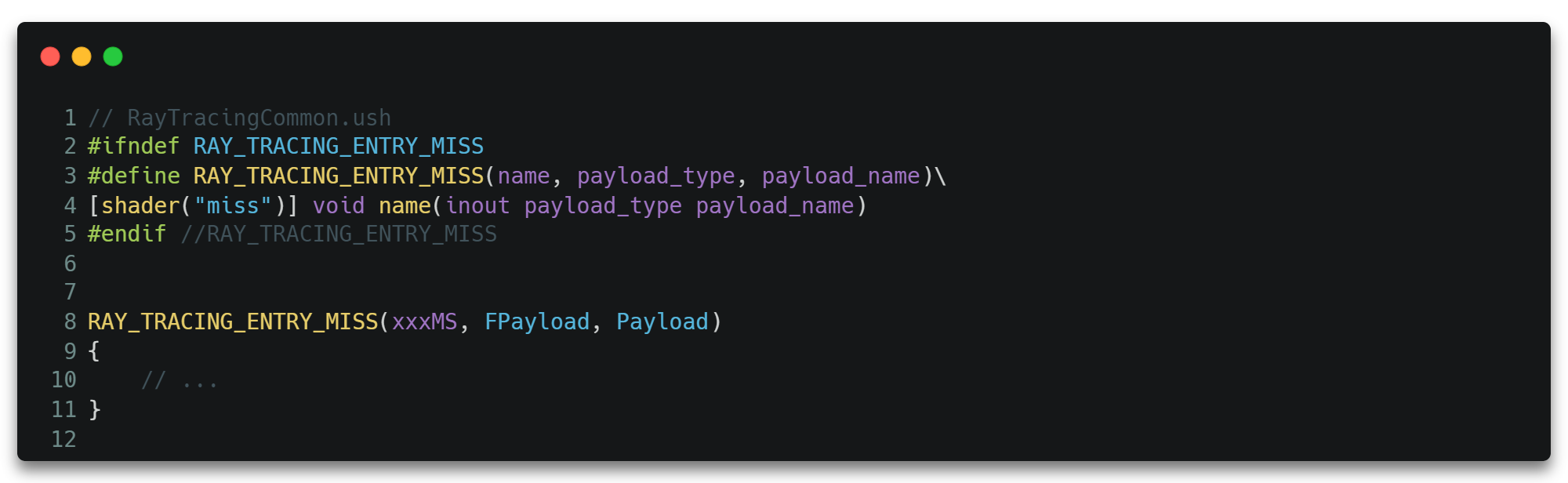
它也有能力再次调用TraceRay()发射新的光线出去。
至此,我们大概解释清楚了如图3-2的流程,但其实这只是一个初步的、大体上的、忽略了超级多细节的轮廓,基于这个轮廓我们只是有条件进一步熟悉DDGI了。
所以这里需要声明的是,在熟悉完DDGI之后,我们会将此处按下未表的诸多细节重新以一个熟客的视角把它们“表”出来,形成一个更加完整、清晰并包含各种内部细节的流程,希望诸位看官稍安勿躁。如果有些躁动的话可以跳过DDGI直接跳到再谈光线追踪管线章节,那其实才是本文的重点。
啥是DDGI
如前文所言,DDGI是一个基于Probe的、基于光线追踪(Ray Tracing Based)的动态漫反射全局光照方案。

如图所示。此处基于Probe的方案大致分为四步。
ProbeGenerate。生成光照探针
probe的位置。RTRadiance。使用
Ray Tracing获取每个probe每个表面的radiance。IrradianceBlend。利用渲染方程对radiance作积分得到irradiance。
Apply。在BasePass中应用irradiance结果。
DDGI基础版
Probe Generate
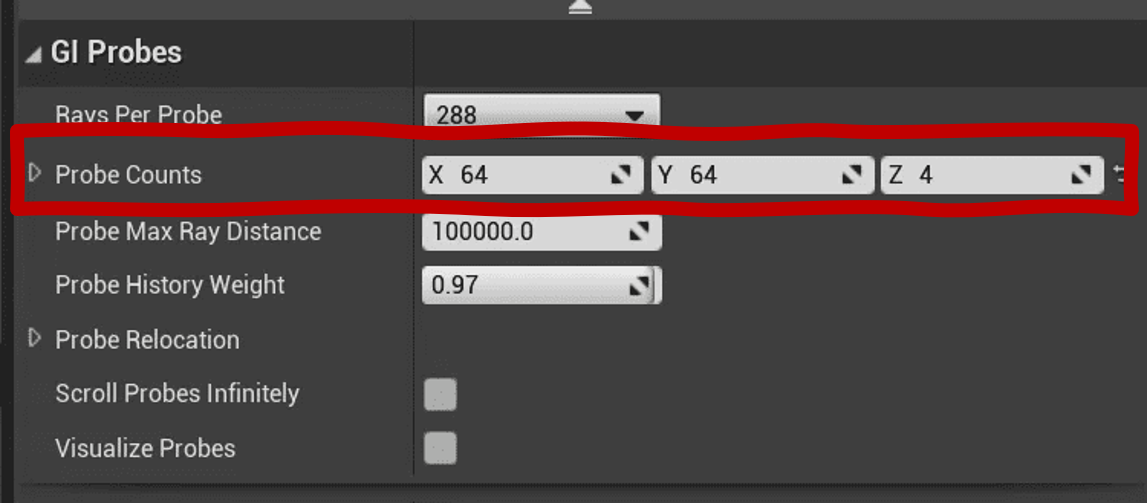
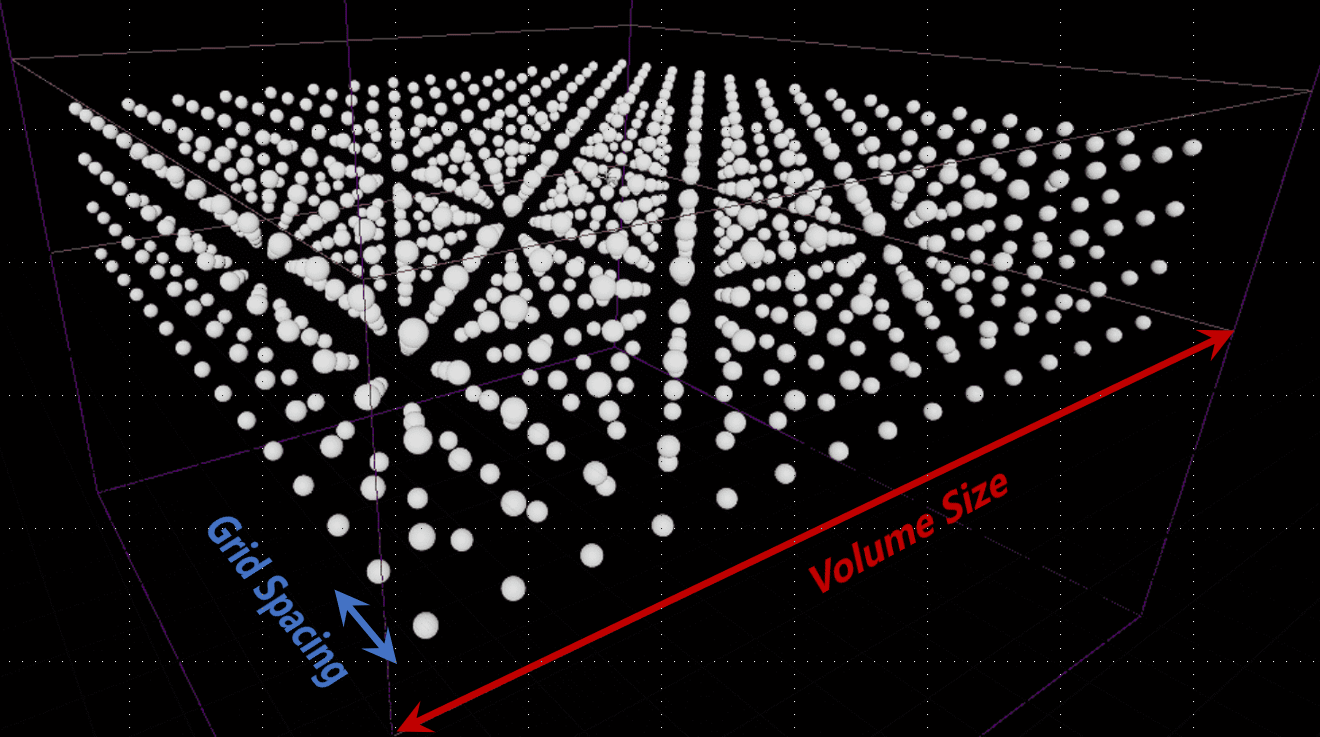
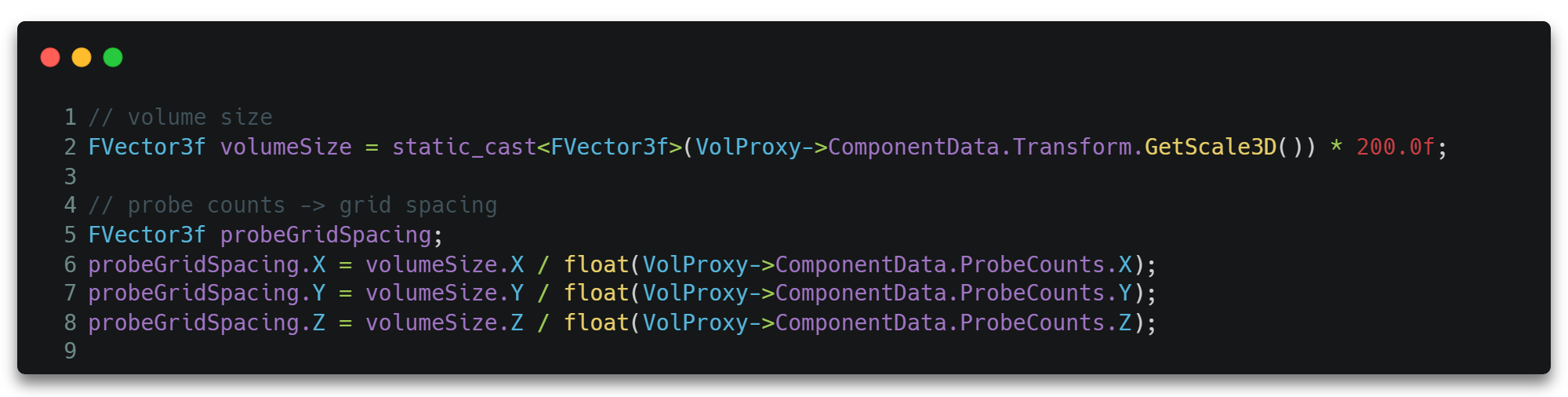
DDGI的计算是在某一个有限范围的体积Volume内的。所以我们通过Volume Size和一个可配置的Probe Counts唯一确定Probe的间距Grid Spacing,从而将场景空间划分为等距的立方体网格。
其由Probe Counts计算得Grid Spacing的代码如下。
Probe Counts等数据可以决定后续并行计算分配的线程数量,决定需要分配的贴图资源,包括用于存储中间结果和最终结果的贴图资源大小等。
RT Radiance
在确定Probe Counts等数据后,我们就可以为每个Probe发射一定数量的光线,并计算每一条光线打到物体表面所产生的光照结果,作为第二次光照的输入。
其中每个Probe发射的数量也是可以配置的。
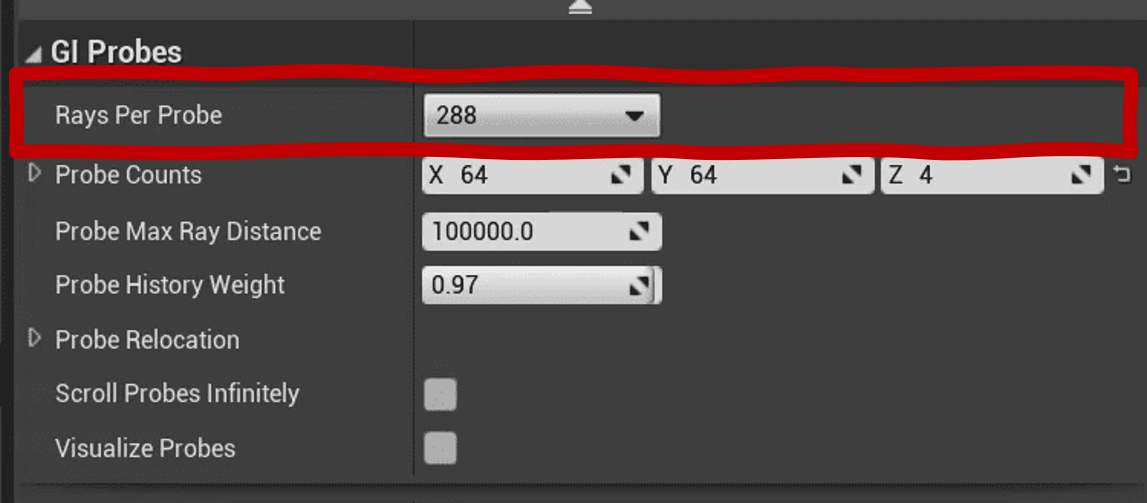
因为我们需要存储每一个Probe的每一条光线,所以总共需要存储ProbeCounts * RaysPerProbe个Radiance数据。所以我们将它们存储在一张x轴大小为ProbeCounts个像素、y轴大小为RaysPerProbe个像素的2D贴图上。
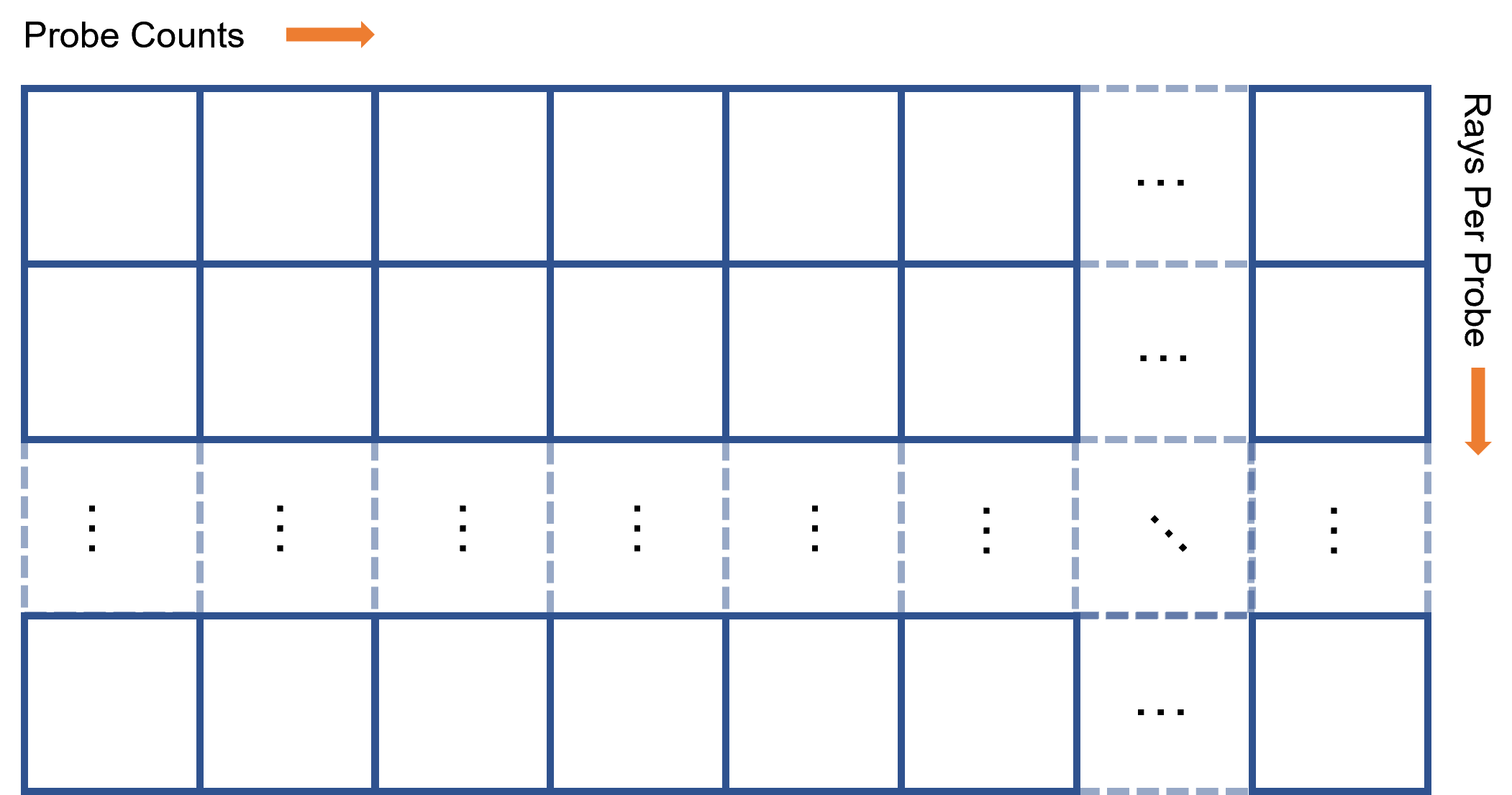
显然我们也要发射ProbeCounts * RaysPerProbe条光线。

对于每条射线,便会通过其RGS,即ProbeUpdateRGS.usf进行并行发射光线,开启RTX流程。
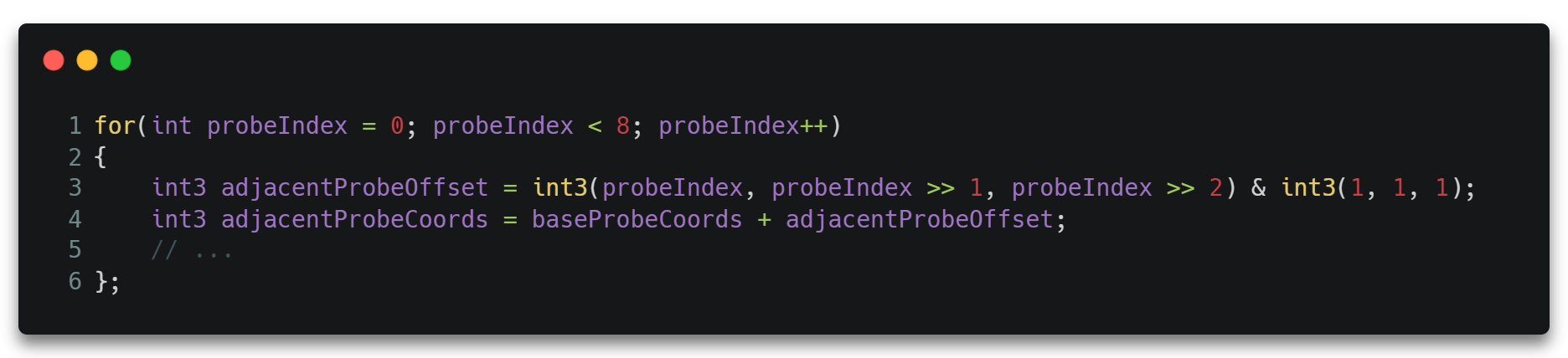
对于每一条光线(每一个线程)的ProbeUpdateRGS.usf,我们会通过ProbeIndex和RayIndex确定一条唯一的光线。

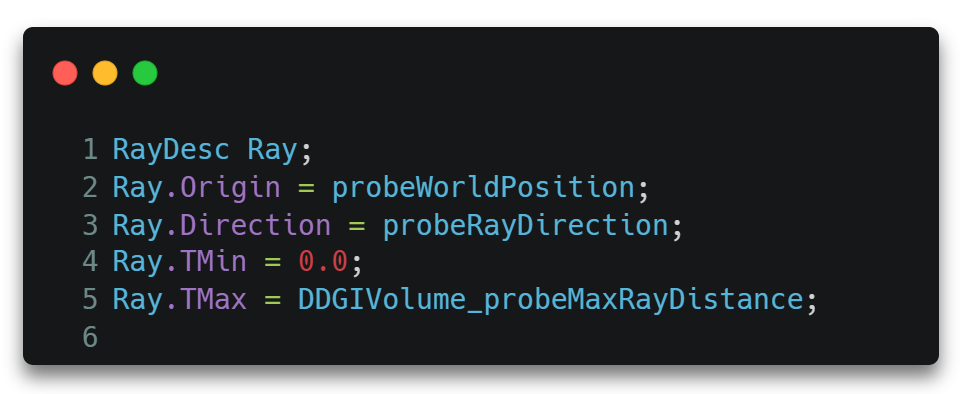
如图所示,一条光线大概由以下几个参数确定。
- Origin。光线的原点。
- Direction。光线的方向。
- TMin/TMax。光线的起止位置。
我们通过ProbeIndex和RayIndex求出光线的原点和方向。其中原点可通过Grid Spacing将ProbeIndex转为3D空间的坐标。而方向则通过RayIndex确定均匀分布的一个方向,通过会使用诸如球面斐波那契(Spherical Fibonacci)等方法获得。

除此之外,我们还要创建自定义数据Payload,以存储光线传递过程中需要传递或回溯的参数。
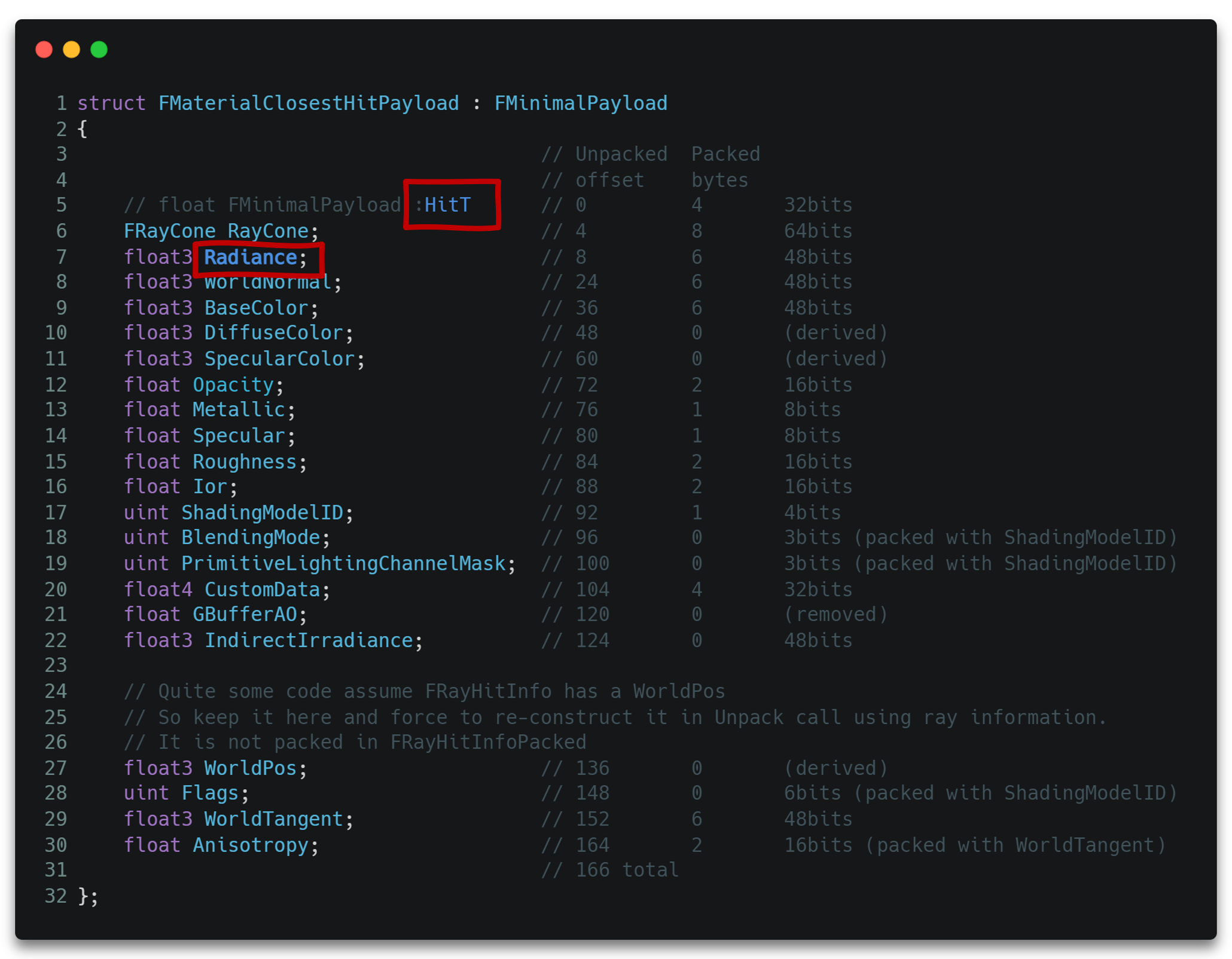
需要注意的是,这里的HitT存储的是碰撞的时间,可以理解为交点处于整条光线范围的比例,通过它我们可以方便地求出交点处的坐标。
1 | HitPosition = Ray.Origin + Ray.Direction * Payload.HitT; |

然后便可将创建好的光线数据RayDesc和自定义数据Payload作为参数调用TraceRay()API。从而真正开启RTX流程。
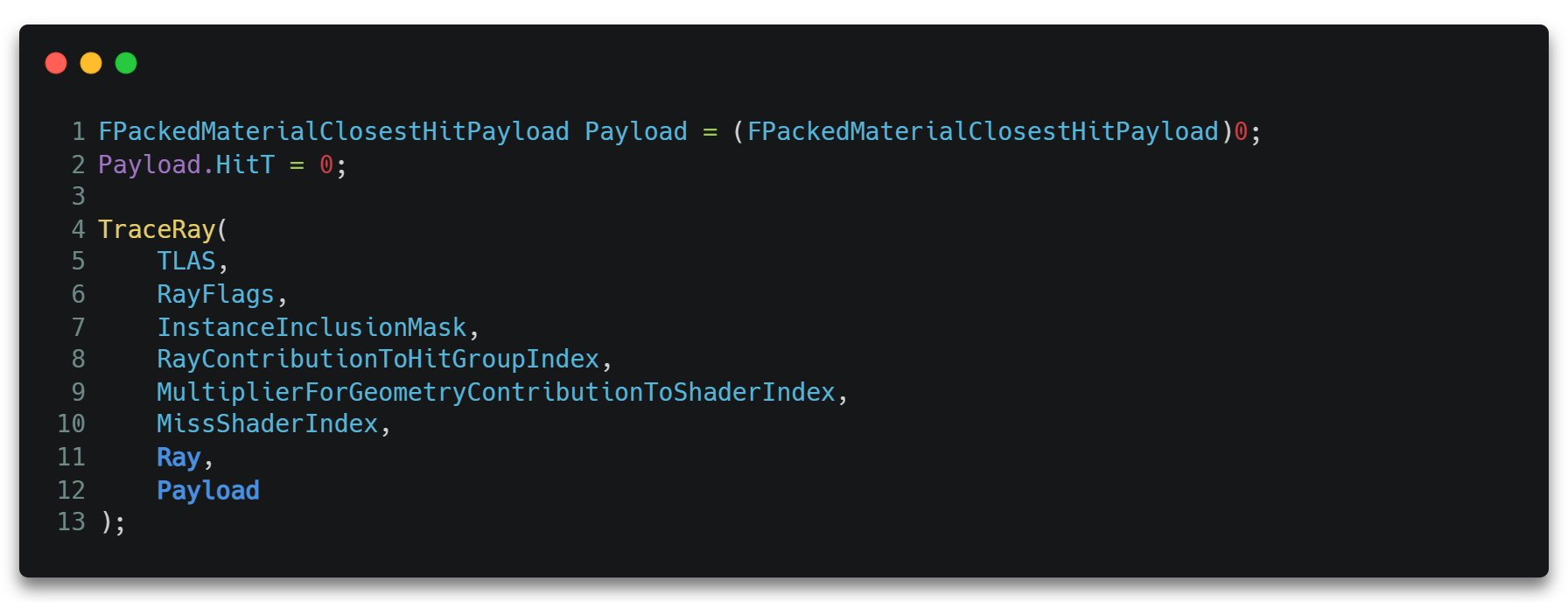
至此,当TraceRay()函数调用完毕回到RGS执行下一条指令时,Payload.Radiance中便存储了第一次光照反弹的输出,即第二次光照反弹的输入Radiance。这也是RTRadiance这一步的最终结果,存储在一张ProbeCounts * RaysPerProbe大小的2D贴图上,如下所示。

*Payload是如何获得Radiance光照数据的
到目前为止,我们可以认为Paylod.Radiance得到结果的过程是一个黑盒,这并不会影响整个DDGI流程。所以笔者可以暂时跳过这一节继续后面的流程,等后面所有与RTX光追有关的章节了解完毕之后再回头重新回到这里分析Payload是如何获得Radiance数据的。
熟悉了整个RTX流程之后很容易知道,当我们第一次调用TraceRay()之后,对于有效的光线与物体表面交点,将会走到CHS里执行,其CHS代码大致如下。
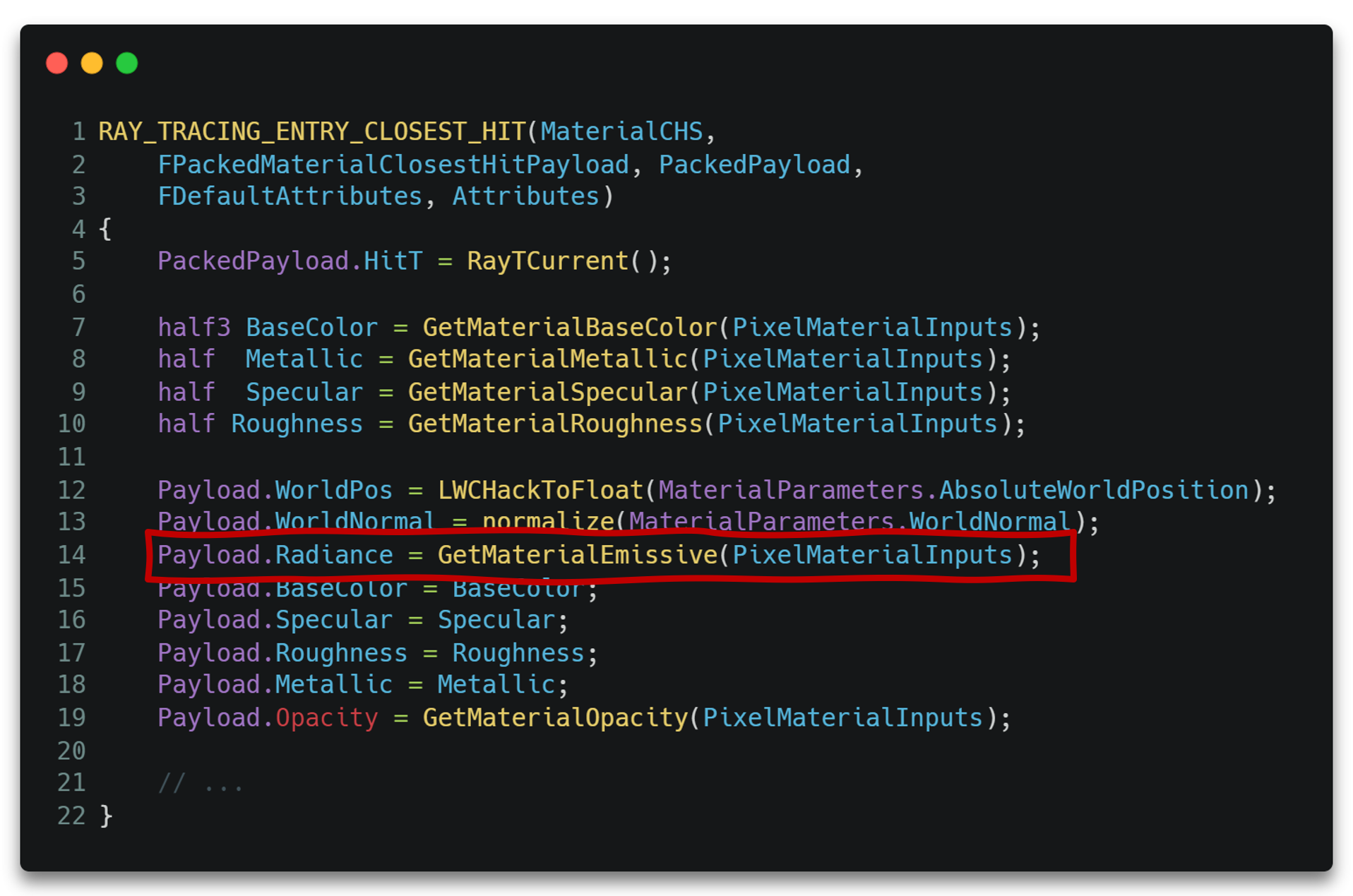
其中Radiance参数存储了材质输入的自发光颜色,Payload的其他参数也存储了其他的材质相关的输入。
当TraceRay()执行完毕后,将回到RGS继续执行接下来的代码。在RGS中,我们接着根据CHS里回溯回来的数据,从交点处向光源方向继续调用TraceRay()发射光线。
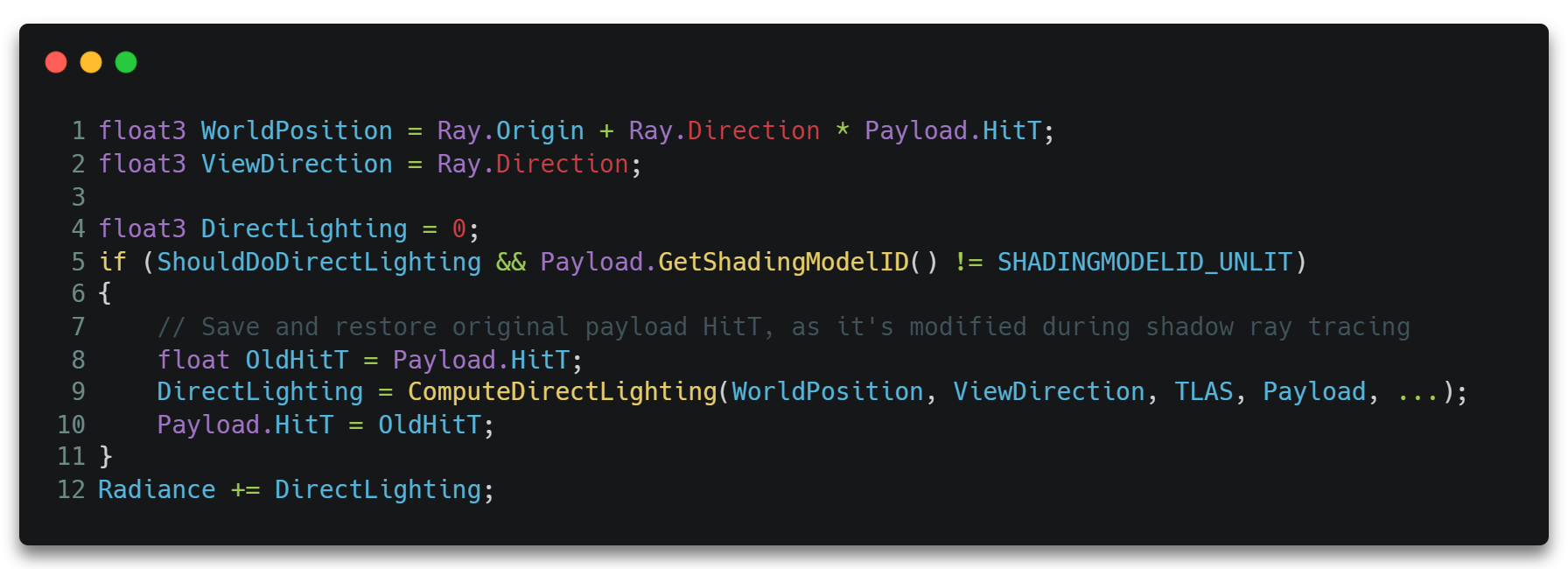
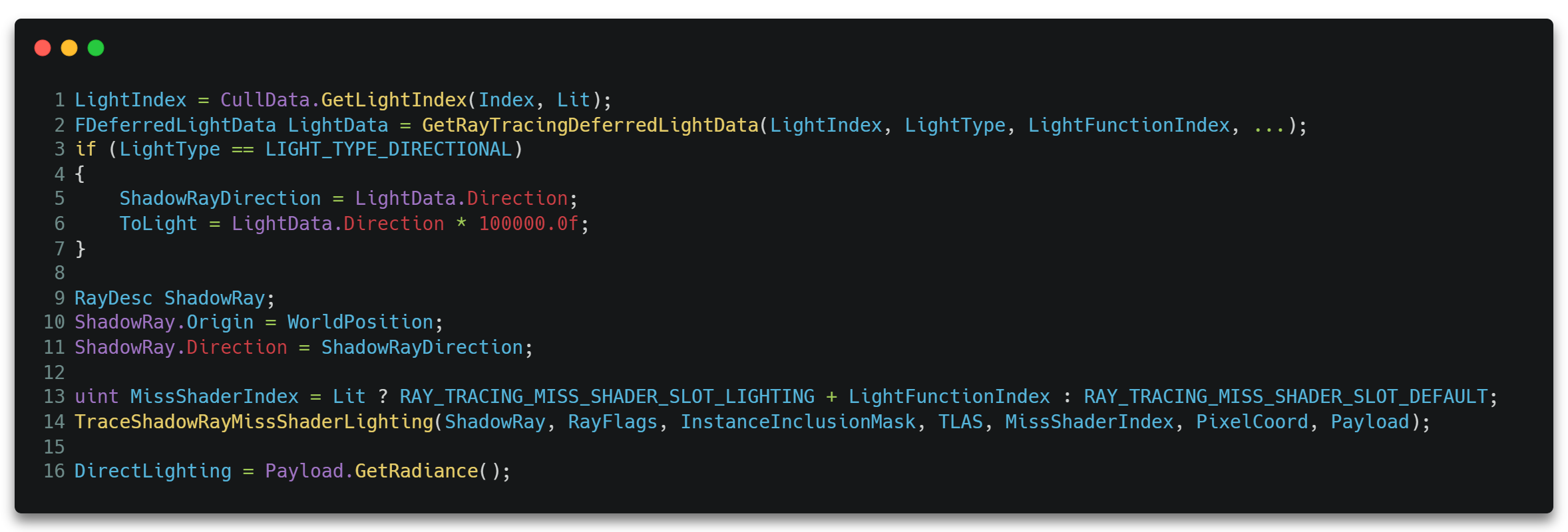
只不过这次TraceRay()需要指定RayType为RAY_TRACING_SHADER_SLOT_SHADOW,且需要设置RayFlags为RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH & RAY_FLAG_SKIP_CLOSEST_HIT_SHADER。从而确保只要有任何交点就丢弃掉那条光线的所有流程,只执行可达光源处的光线的MS。
并且需要根据光源类型设置对应的MissShaderIndex。
这样一来,在某个光源对应的MS里,便是直接进行光照着色计算,并将结果存储到Payload的过程了。这里使用Payload数据生成了一份GBufferData,之后便可使用光栅化管线的接口GetDynamicLighting()进行着色了。
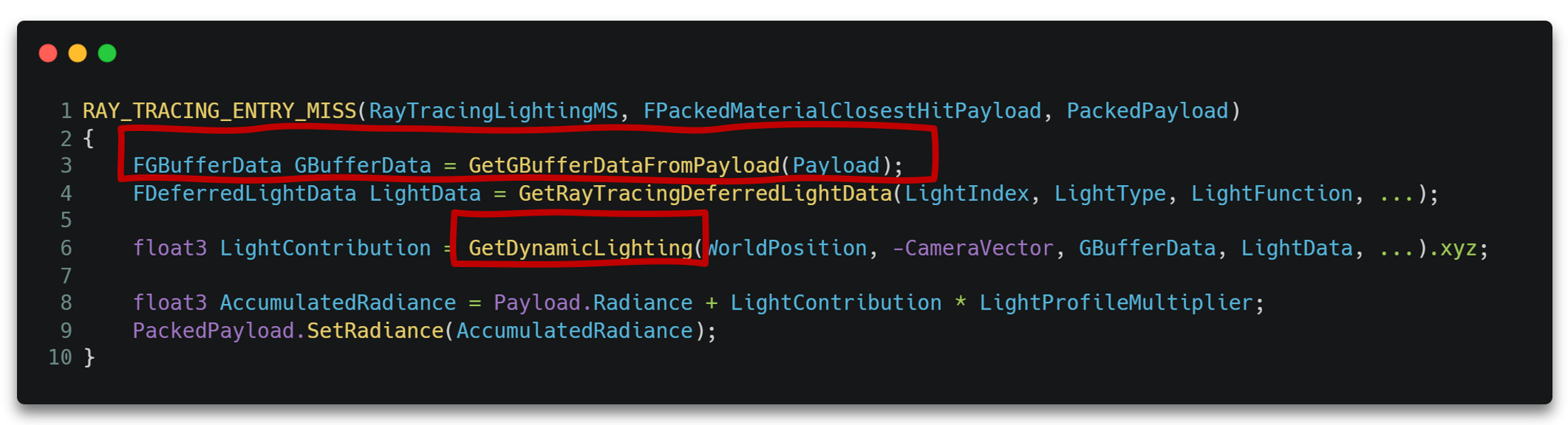
Irradiance Blend
有了上一步的Radiance,我们就可以计算每个Probe的Irradiance数据了,该步计算位于ProbeBlendingCS.usf。
我们知道,一个着色表面是由位置和法线确定的。而一个Probe代表了他周围的着色表面,当它代表某一个表面时,需要从该Probe上找到与该表面法线相同的数据。所以Probe理应存储所有法线方向的数据才行。但这显然是存不下的,所以我们需要离散化成有限数量个法线方向,其他方向通过这些方向插值得到。我们暂且先认为一个Probe需要计算n个法线方向的结果。
所以我们总共需要ProbeCounts * n个像素来存储Irradiance结果,如下图所示。
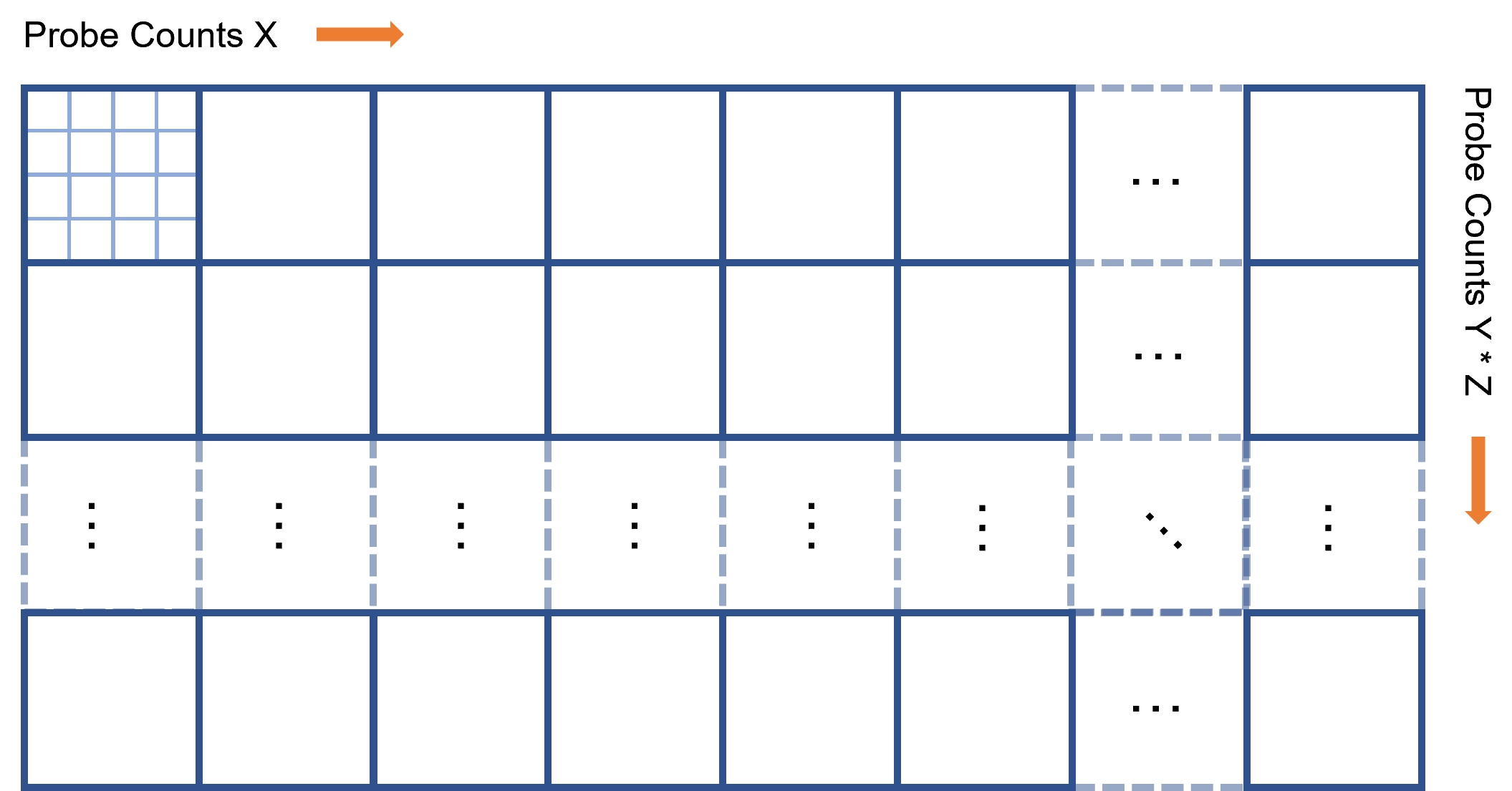
计算Irradiance的过程也是一个并行过程,其中每个Probe的每个法线方向分配一个线程。
我们只对于一个确定的法线方向来看是如何计算的。显然,对于一个确定的法线方向,有一个唯一确定的渲染半球积分与之对应。

自然也有唯一确定的循环代码与之对应。
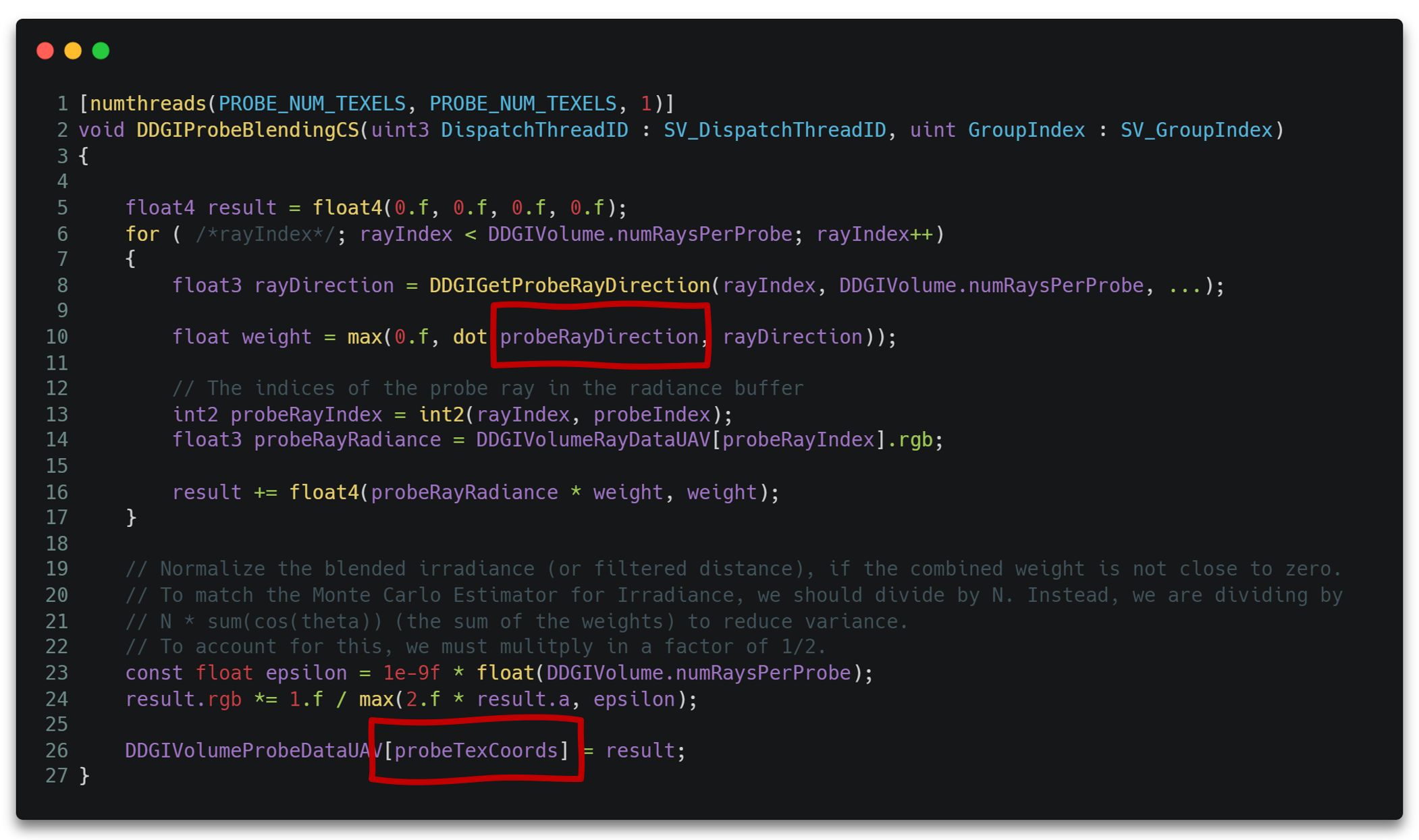
这里使用正八面体映射(Octahedral Map)来将球面6*6个法线编码到2D贴图8*8的像素上。
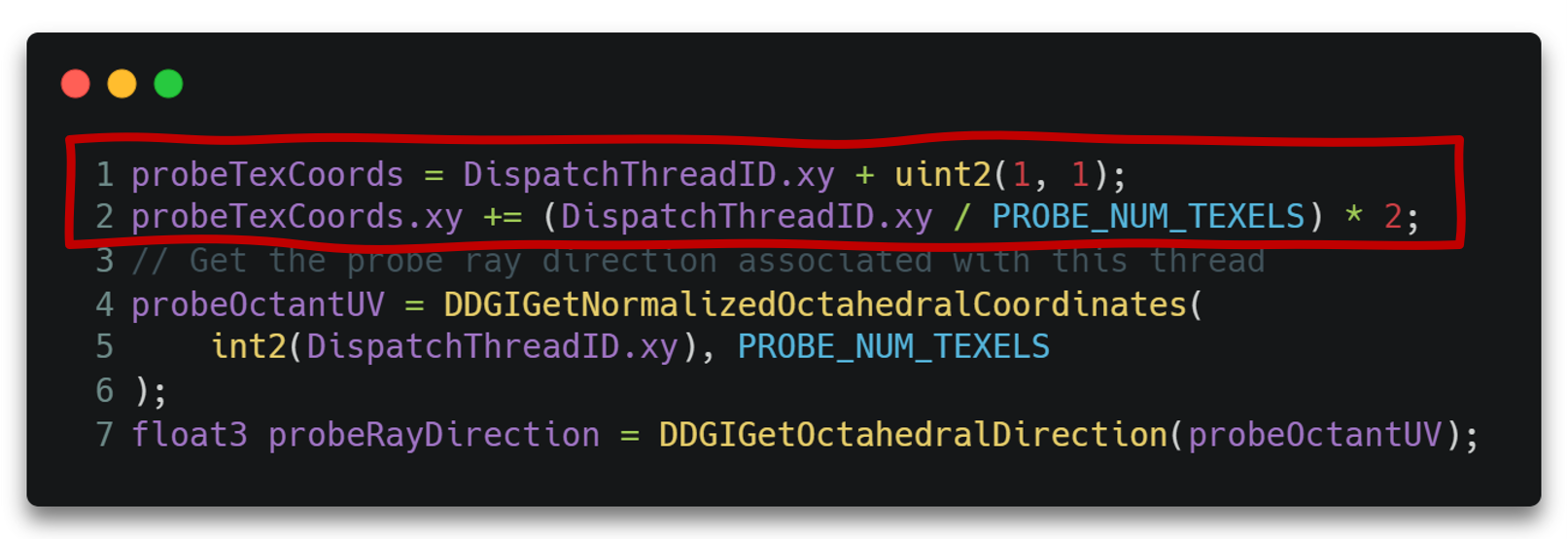
其镶边操作位于ProbeBorderUpdateCS.usf中。
最终Irradiance结果存储在一张(ProbeCntX * 8, ProbeCntY*ProbeCntZ * 8)的2D贴图上,如下所示。

Apply
Apply阶段将求得的Irradiance结果在BasePass中采样,其中对于每一个着色点,都将采样周围八个像素的Probe结果并进行三线性插值得到最终的结果。这里忽略了其他为了减少漏光或者提升表现的权重项。

Life Cycle
DDGI使用一种插件化的实现方式,将功能与引擎本身解耦,使得引擎察觉不到该模块的存在。
这里使用到的核心思想是依赖倒置DIP。在引擎模块中调用了一些抽象代理接口控制流程和生命周期,但并不依赖具体的实现。而在DDGI模块中则绑定引擎的这些抽象代理,从而获取引擎的生命周期和数据。形成DDGi依赖引擎而非引擎依赖DDGI的倒置。
总的生命周期流程图如下所示。
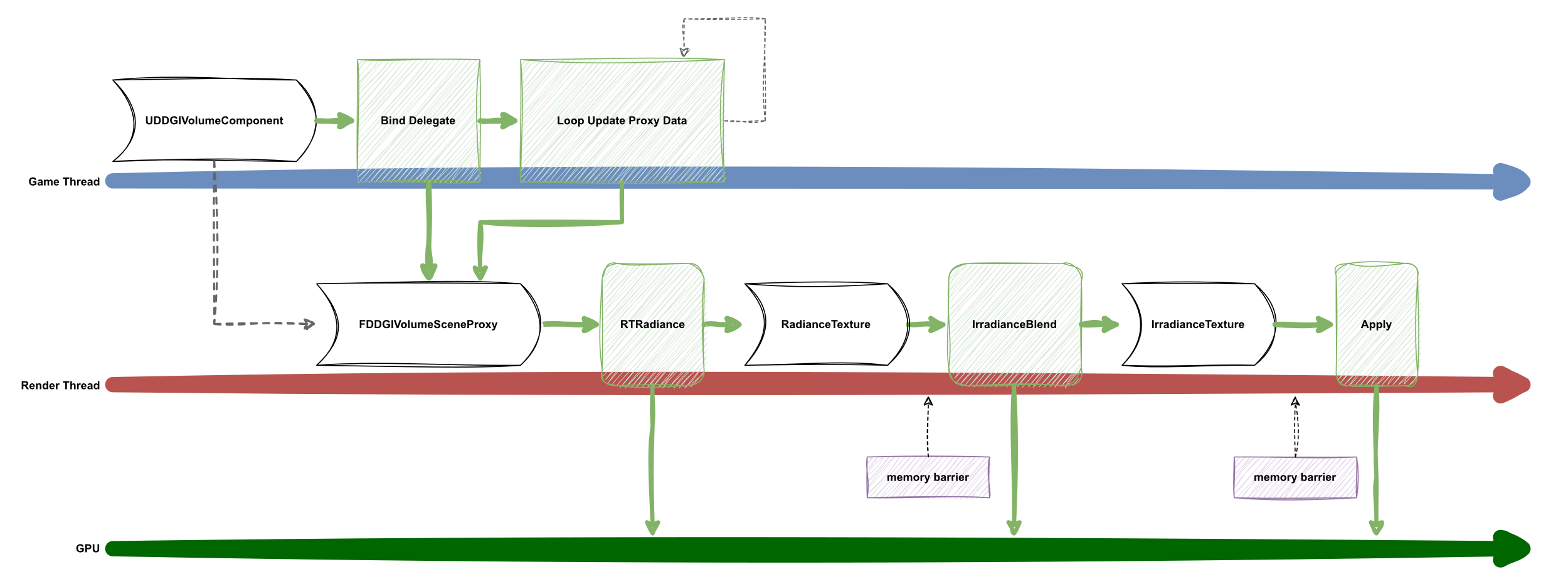
至此,一个包含RTX精髓的基础版DDGI便实现了。但其实还有一些更进一步的功能实现才能使DDGI更准确且易用,下面简单罗列一些仅供参考。
DDGI进阶版
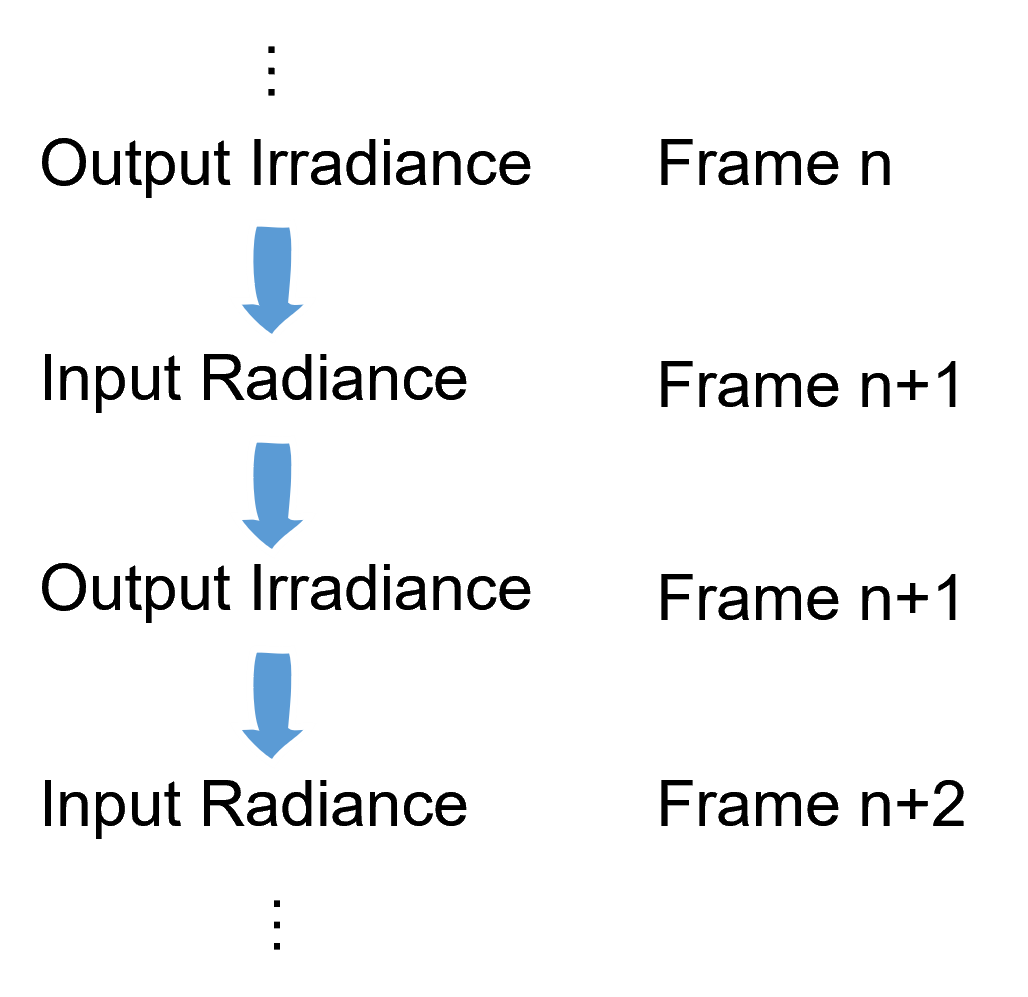
Multiple Bounds
在RTRadiance阶段像BasePass阶段Apply一样采样Irradiance,使用上一次的间接光结果作为这一次的直接光输入,即可实现多次反弹。
Infinite Scrolling
当DDGI Volume在大世界中移动时,我们并不需要时刻都重新生成所有的Probe。只需要维护一个Probe ScrollOffsets记录所有Probe在Volume的本地坐标空间内偏移的向量即可。这样只需要额外一步转换即可计算出相同世界坐标对应的Probe在移动后的Volume中的Irradiance贴图中的新的采样位置。

与此同时,还需要一份Probe State数据以避免还没有移出Volume范围的旧的Probe再次计算。
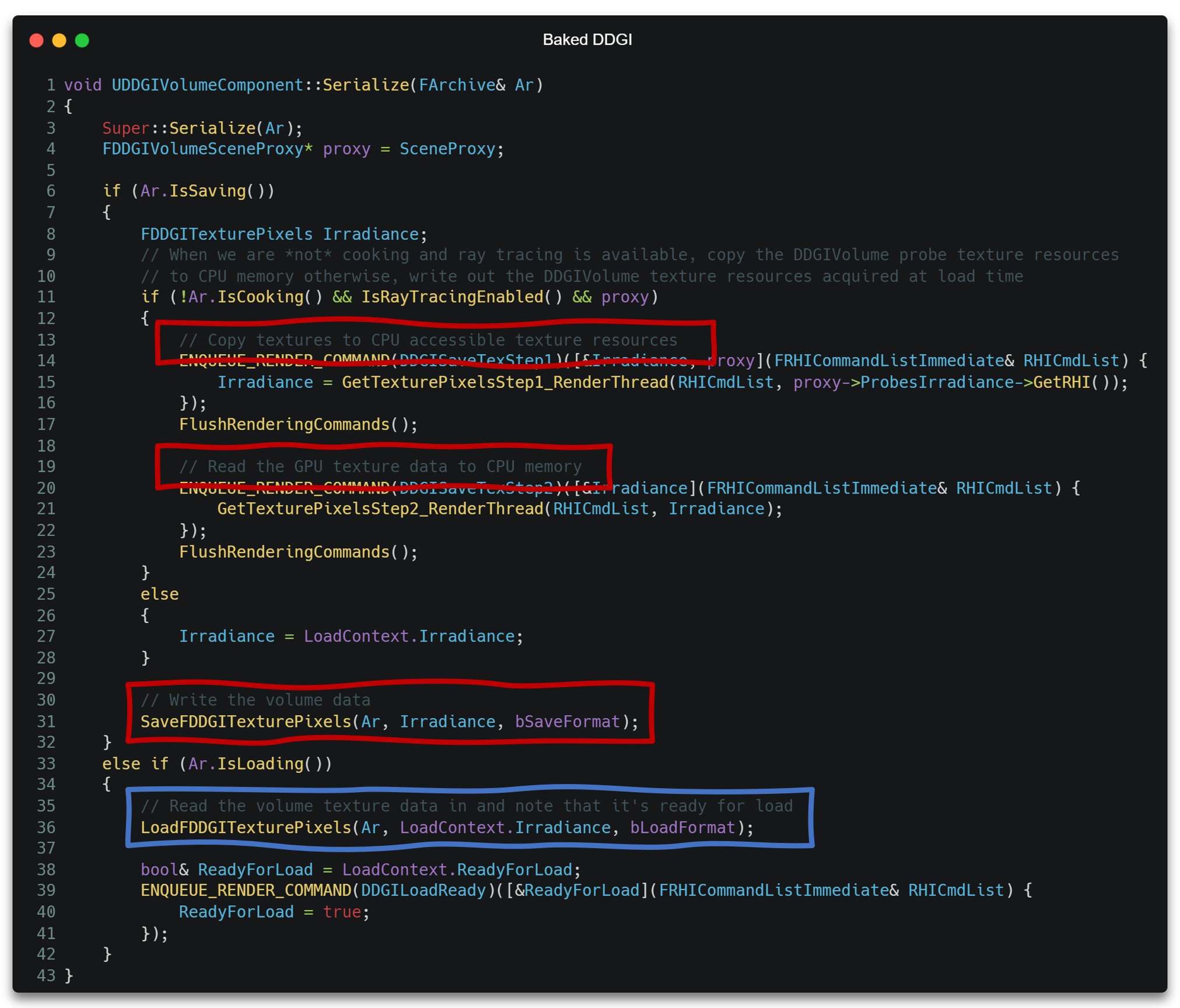
Baked DDGI
对于静态光源和静态场景,DDGI也支持将计算的数据序列化到磁盘存取,从而达到Baked功能。
该功能只需要在序列化到磁盘时将Irradiance及Apply时所用参数一起序列化到磁盘,并在从磁盘读取时使用序列化数据重建这部分数据即可。
Avoids Leaks
DDGI提供了两种抑制漏光的方法,如下所示。
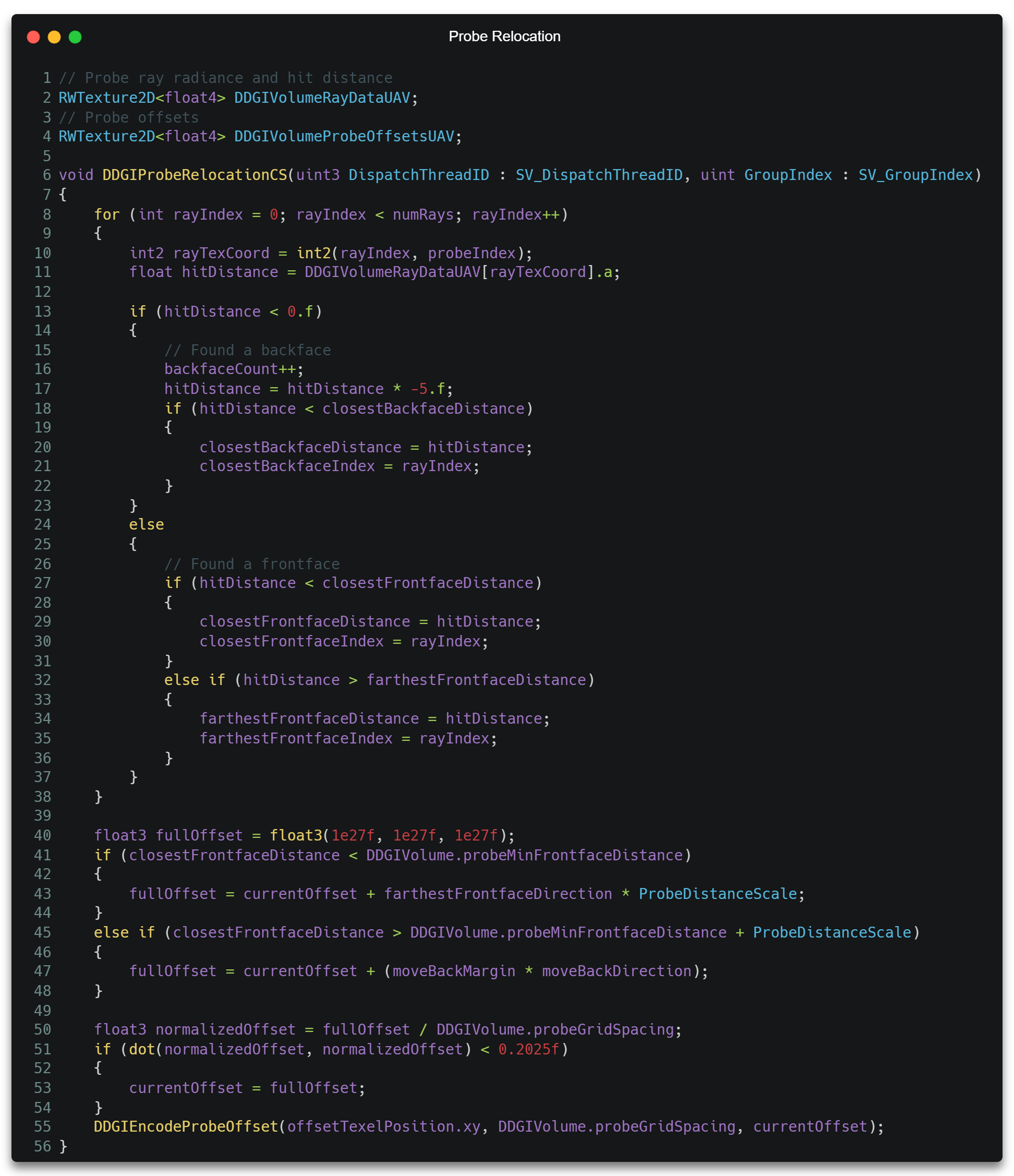
Relocation
一种方法是通过Ray Tracing阶段获取到的交点数据(HitT)等对Probe的位置进行重新修正,如使其沿光线方向远离交点。
Chebyshev Inequality
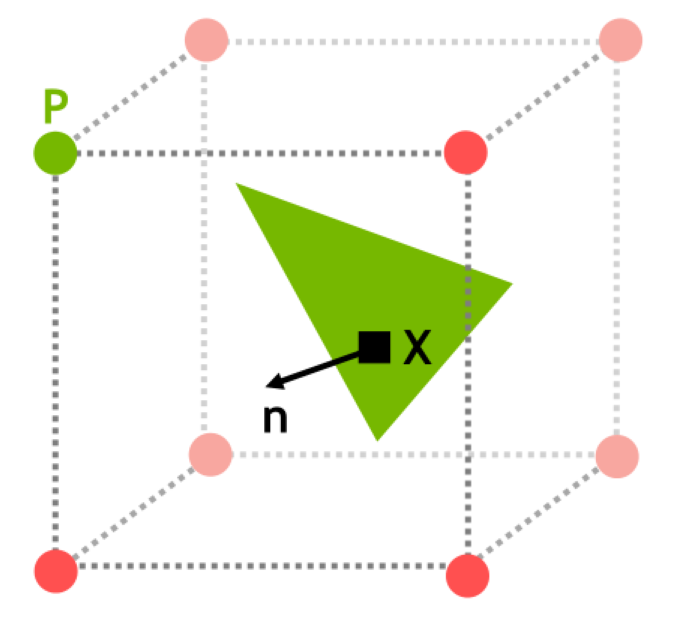
另一种方法是利用切比雪夫不等式(Chebyshev Inequality)来估计一个Probe与着色点之间可见(无遮挡)的概率。
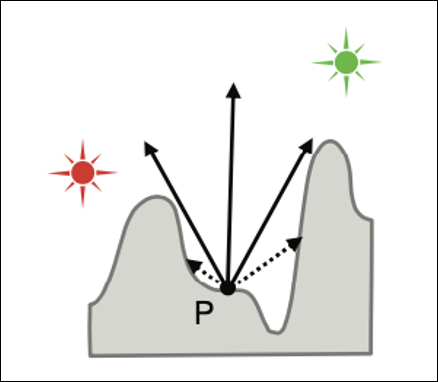
设这个概率为P(r > d)。其中
r:
Probe到着色点方向能看到的最近的物体的距离(各个方向的深度)。如下图蓝色箭头所示。d: Probe与着色点的距离(
length(probePos, SurfacePos))。如下图红色箭头所示。P(r > d) == 0 : 所有方向的r都小于d,完全遮挡。如下图红色点所示。
P(r > d) == 1 : 所有方向的r都大于d,完全可见。如下图绿色点所示。
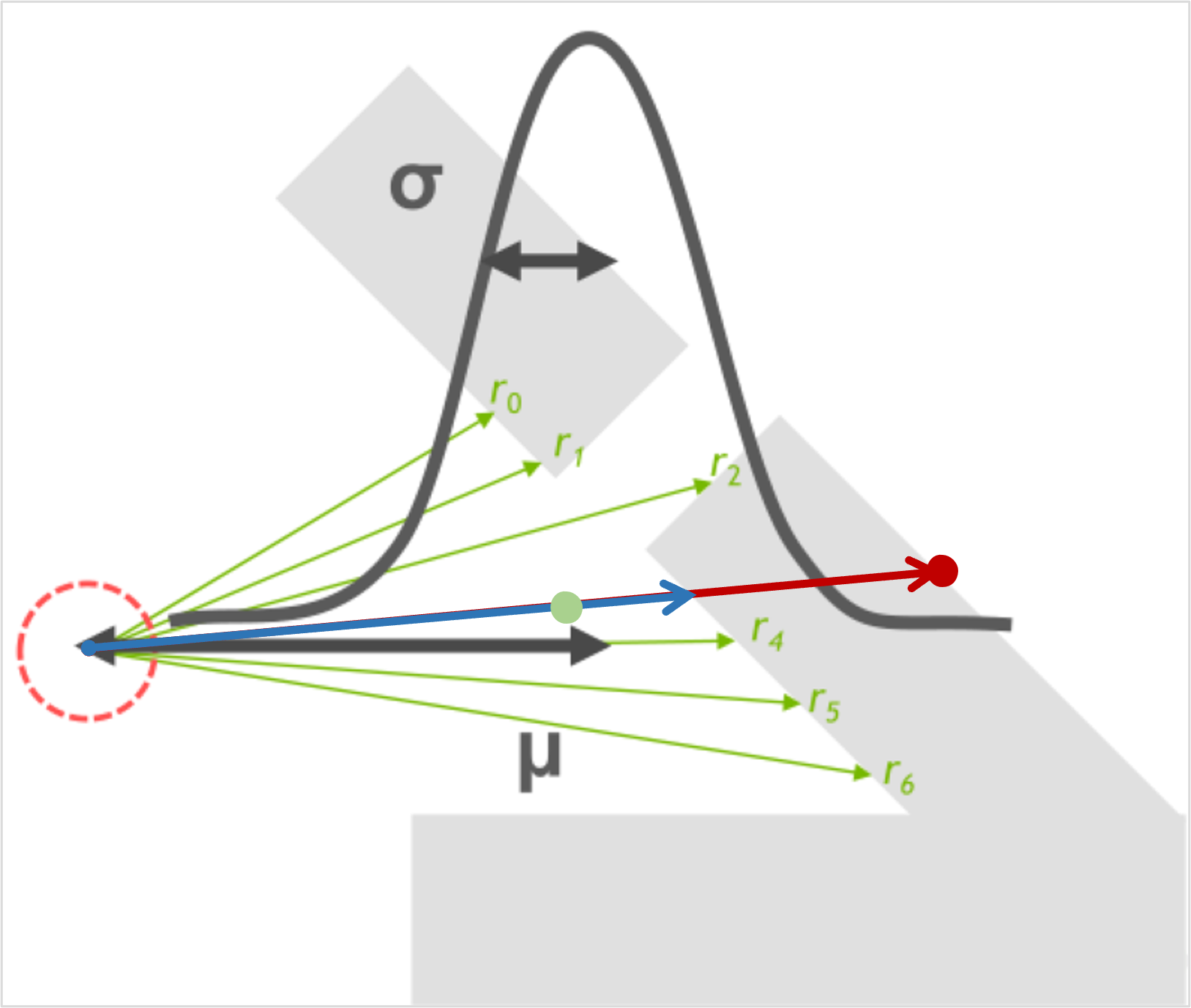
我们使用切比雪夫不等式(Chebyshev Inequality)来预估这个概率的上界,并乐观地认为总能达到上界。
\[ P(r > d) \le \frac{\sigma^2}{\sigma^2 + (d - \mu)^2},d > \mu \]
其中r为随机变量,\(\mu\)为r的均值,\(sigma\)为r的方差。
随着d的增大,这个上界越来越小,说明距离Probe越远,越容易被遮挡。
而当\(d < \mu\)时,我们认为着色点完全在Probe的可见范围内,是完全可见的。
事实上,这里的不等式其实并非切比雪夫不等式(Chebyshev Inequality),而是坎泰利不等式(Cantelli Inequality)的一个单边形式,Cantelli Inequality如下。
\[ \left\{ \begin{array}{l} P(X-\mu\geq\epsilon)&\leq&\dfrac{\sigma^2}{\sigma^2+\epsilon^2},& (a) \\ P(X-\mu\leq-\epsilon)&\leq&\dfrac{\sigma^2}{\sigma^2+\epsilon^2}, & (b) \\ \end{array} \right. \]
对于(a)式, 令
\[ \left\{ \begin{array}{l} X = r \\ \epsilon = d - \mu \end{array} \right. \]
即可得我们所用的公式。而它是由真正的切比雪夫不等式推导来的,真正的切比雪夫不等式如下。
\[ P(\vert{X-\mu}\vert>\epsilon)\leq\dfrac{\sigma^2}{\epsilon^2} \]
它可由马尔可夫不等式(Markov Inequality)证明,Markov Inequality如下所示。
\[ P(X\geq\epsilon)\leq\dfrac{\mathbb{E}[X]}{\epsilon} \]
而Markov Inequality则可以由全概率公式简单证明。
\[ \begin{aligned} \mathbb{E}[X]&=\mathbb{E}[X\vert X\geq\epsilon]\Pr(X\geq\epsilon)+\mathbb{E}[X\vert X<\epsilon]\Pr(X<\epsilon)\\ &\geq\mathbb{E}[X\vert X\geq\epsilon]\Pr(X\geq\epsilon)\\ &\geq\epsilon\Pr(X\geq\epsilon)\\ \dfrac{\mathbb{E}[X]}{\epsilon}&\geq\Pr(X\geq\epsilon) \end{aligned} \]
DDGI典藏版
关于SDF DDGI,限于篇幅和时间关系就不在此篇展开了,后续会在距离场专题中重新提及。
再谈光线追踪管线
在了解完DDGI的使用之后,我们对光线追踪过程有了一个更具像的体验,那么是时候更进一步把前文啥是光线追踪章节里所有暂且按下不表的地方翻出来看看了。
加速结构
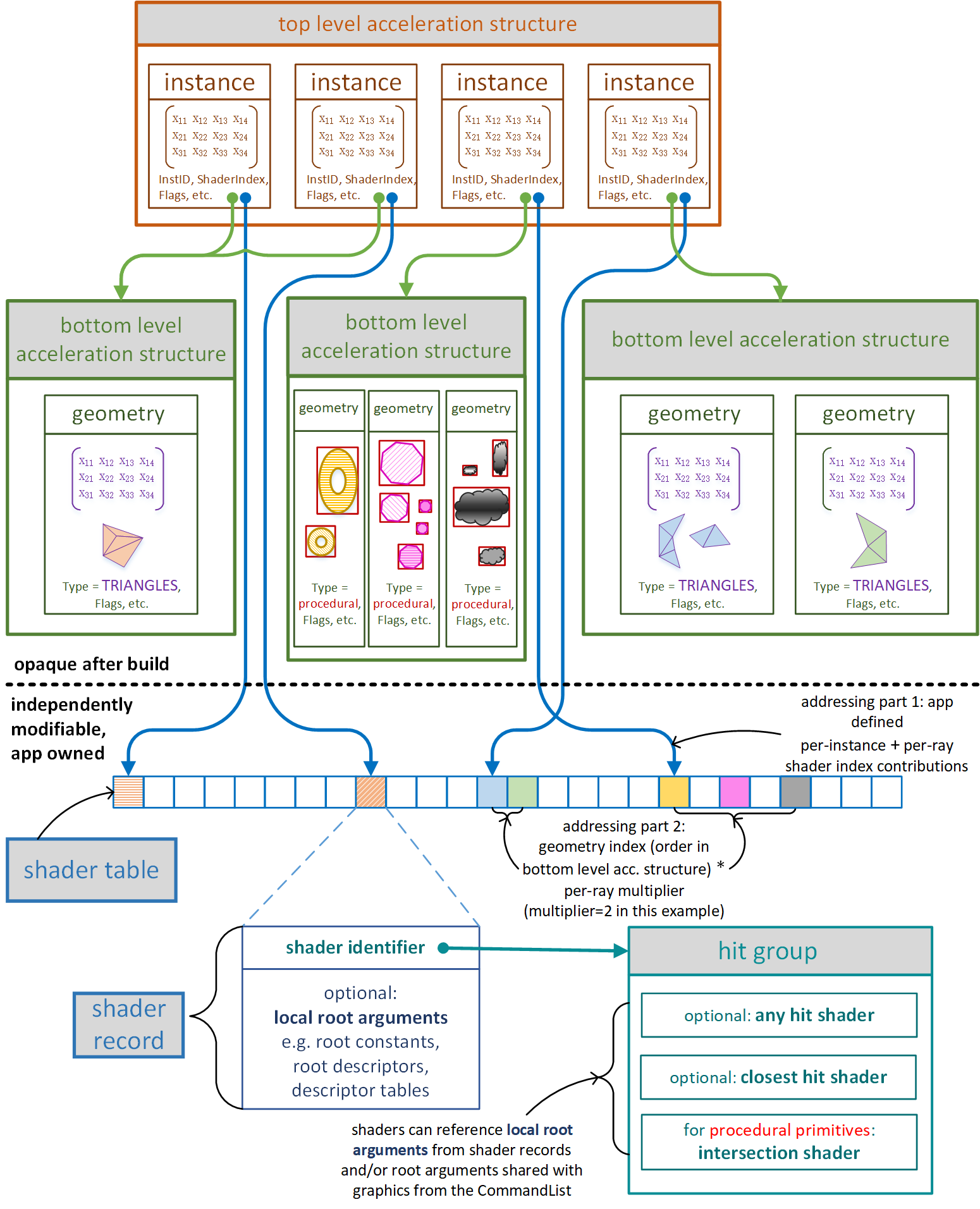
加速结构(Acceleration Structure)是场景信息在GPU侧的描述。如上图所示,RTX中的加速结构是一个双层的结构,即底层加速结构(bottom-level acceleration,BLAS)和上层加速结构(top-level acceleration structures, TLAS)。
BLAS
BLAS是由三角形图元(默认)或AABB包围盒(自定义)作为几何体(Geometry)节点组成的加速结构,一个BLAS结构有多个Geometry。
当BLAS的基元为三角形图元时,一个Geometry内的三角形的数量可以是任意的。除此之外,还将包含一个3x4的行主矩阵,表示三角形图元在该几何体中的Transform矩阵。
当BLAS的基元为程序化几何体(procedural)时,一个Geometry内的AABB包围盒数量也可以是任意的。一般一个场景物体可使用一个或多个AABB插入其中。而IS的触发是对每一个AABB而言的,即每一个AABB触发一次。
如果是使用了程序化几何体,那么BLAS里存储的只是AABB包围盒的数据,其与具体物体的关联通过一致的下标或ID来保持。
一个Geometry同时还包含了图元类型(Type)、图元标记(Flags)等其他信息。
我们通过D3D12_RAYTRACING_GEOMETRY_DESC来定义一个Geometry的结构。
TLAS
TLAS是由实例(Instance)作为节点组成的加速结构。此处实例的含义是,它内部使用InstID指向某一个BLAS,同时存储该BLAS在世界坐标下的变换矩阵、ShaderIndex、实例的Flags等额外信息。
我们通过D3D12_RAYTRACING_INSTANCE_DESC来定义一个Instance的结构。
这种双层的加速结构,让我们可以在性能和灵活性之间掌握平衡。如果需要更好的性能,则可能需要使用更大规模的BLAS,即单个BLAS复杂度高,总的BLAS数量少,TLAS节点数量少,便于查询。如果需要更大的灵活性,则需要更小规模的BALS,即单个BLAS复杂度低,总的BLAS数量多,TLAS节点数量多,查询消耗比较大,但更新更方便。这是因为对于BLAS我们只能更新顶点位置之类的,但TLAS可更新的数据就比较多了。
我们通过dxR API BuildRaytracingAccelerationStructure()[10]来创建加速结构,并通过D3D12_RAYTRACING_ACCELERATION_STRUCTURE_BUILD_FLAGS来标记其是否可以被更新。

Shader Table
从图8-1可以看出,TLAS中的每一个节点,都有一个指向叫做Shader Table的结构的某一个元素的成员ShaderIndex。
这是因为对于拥有不同材质的物体,它们与光线的求交方式、交点处的表面光照属性等都有所不同。所以在RTX管线中,我们可能需要为不同的材质使用不同的IS、AHS和CHS。这三种与材质相关shader会被捆绑在一起,叫做Hit Groups(HG)。而TLAS里的ShaderIndex,便是指向在Shader Table中的Hit Group索引。
除此之外,对于同一个材质,由于光线类型(RayType)的不同,也可能会使用不同的Hit Group,如对于用作计算阴影的光线,它的Hit Group中可以不需要CHS,且AHS也是调用AcceptHitAndEndSearch()即可,这就跟常规计算表面着色的光线有所不同。
在ue里定义了两种RayType,如下所示。
1 |
所以通过ShaderIndex和RayType就可以唯一确定ShaderTable上的一个Hit Group。如下图所示。
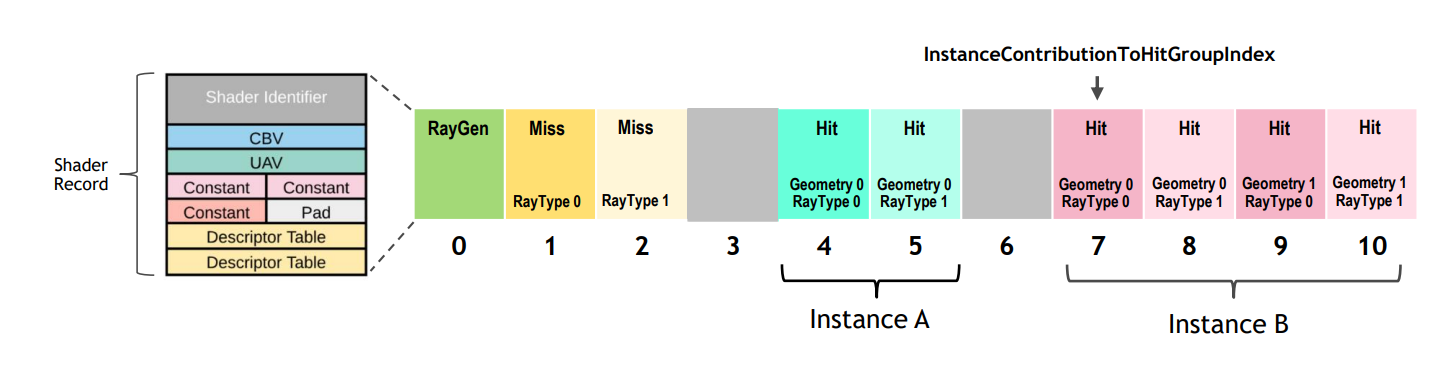
这里的RayType其实来自TraceRay()的参数,我们在前面的章节中曾经按下未表。
RayContributionToHitGroupIndex。对应
RayType的值。MultiplierForGeometryContributionToShaderIndex。对应
RayType的数量。
显然,对于每个材质都独有一份的Hit Groups,其相关的shader里自然都是可以拿到当前碰撞点基元的材质信息的,但一般我们只推荐在CHS里真正获取材质相关属性进行计算,因为IS和AHS本质上还是对交点的选取策略。CHS才是确定了真正的交点之后进行材质计算等的好时机。
从上图也可以看出,RGS和MS便与材质无关了,其中RGS对于一次完整的RTX流程只有一个。而MS的数量则与光源类型(LightType)有关,表示光线打到不同的光源时需要触发不同的计算。
在ue里LightType的定义如下。
1 |
这里可以根据RAY_TRACING_MAX_LIGHT_FUNCTIONS个光照函数来决定光源的计算细节,所以总的MS的数量为RAY_TRACING_NUM_MISS_SHADER_SLOTS + RAY_TRACING_MAX_LIGHT_FUNCTIONS。
这里的LightType其实也是来自TraceRay()的参数,即
- MissShaderIndex。对应
LightType的值。
RayTracing Pipline
以ue为例,对于五种shader,我们只需要进行三类shader创建,这是因为Hit Goups相关的三个shader被绑定在了一起。



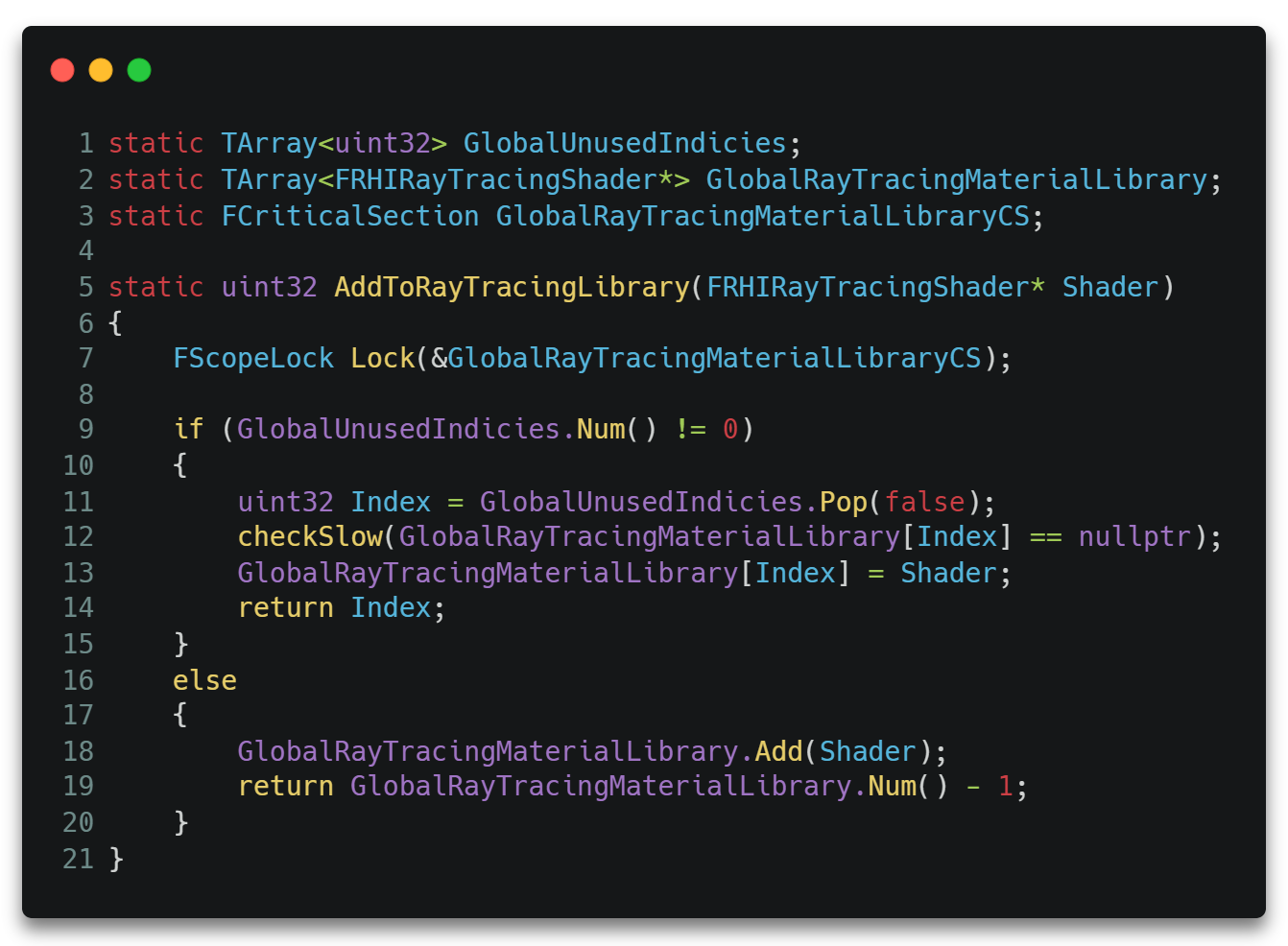
RayTracing管线的绑定入口位于FDeferredShadingSceneRenderer::BindRayTracingMaterialPipeline()。其主要流程便是绑定各类shader到ShaderTable,并调用GetAndOrCreateRayTracingPipelineState()创建真正的Pipeline对象。
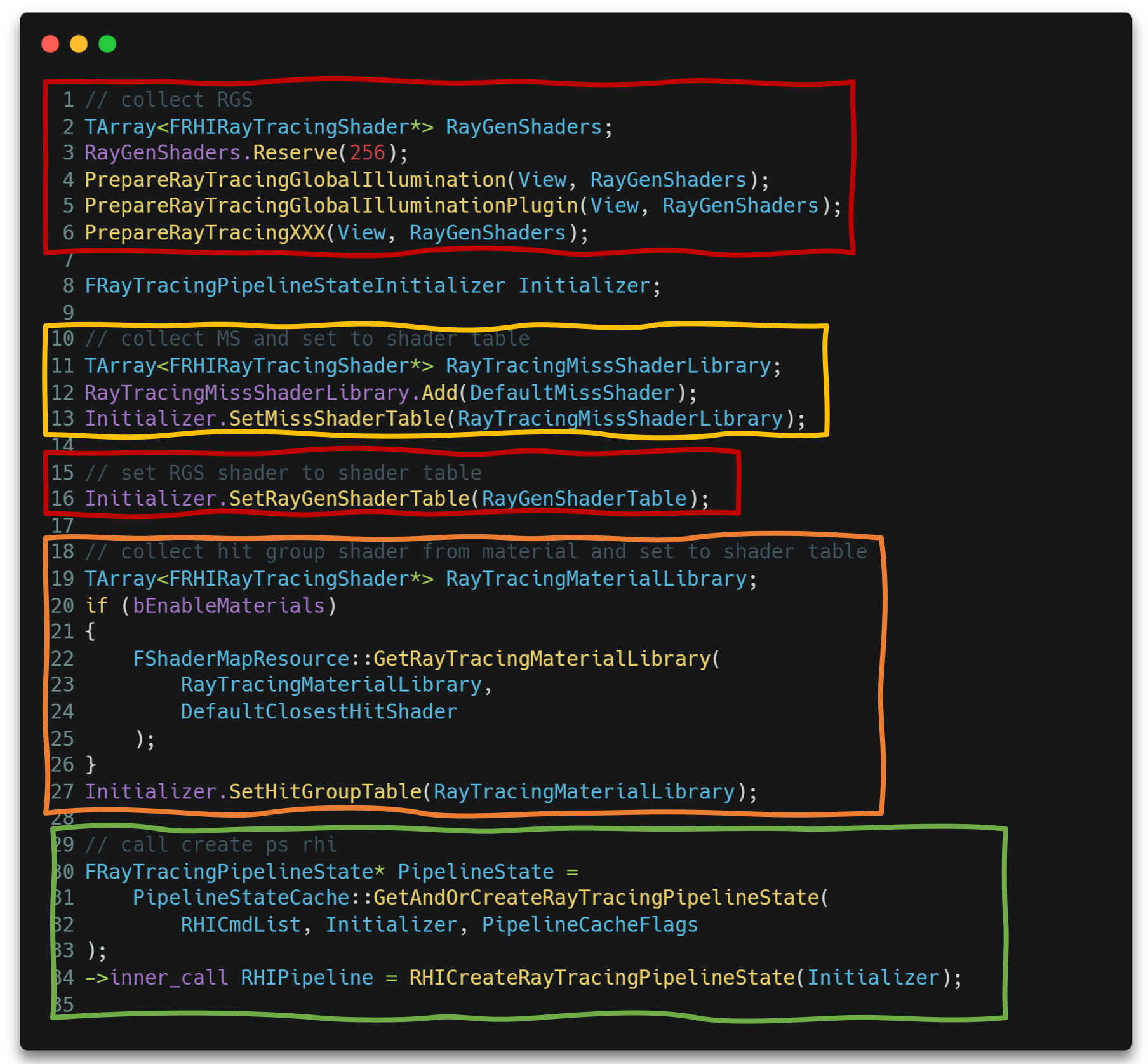
需要说明的是,这里的Hit Groups由于与材质相关,所以其收集过程是从物体绘制时GetShader()开始的,其调用过程大致如下。
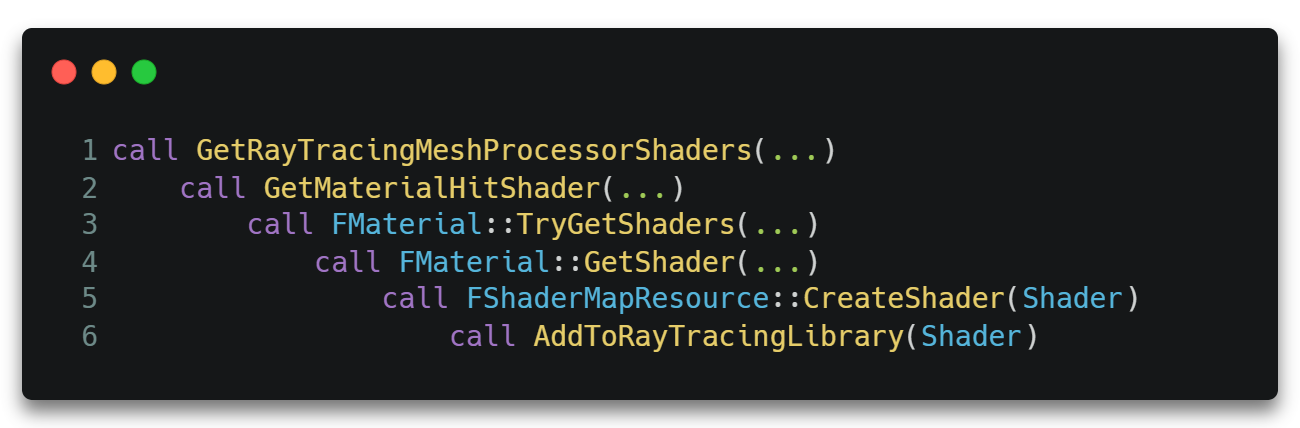
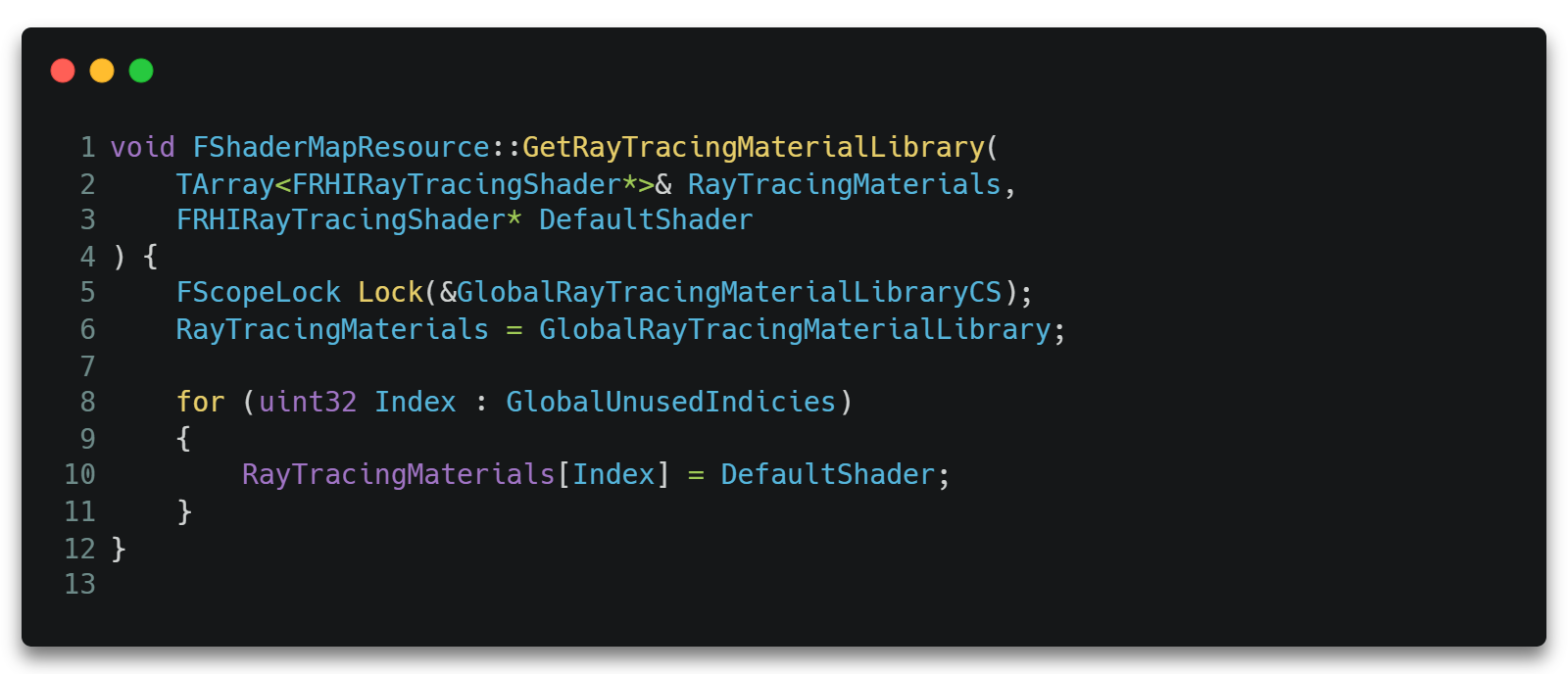
在AddToRayTracingLibrary()中,HG将会被添加进一个全局的Shader数组即GlobalRayTracingMaterialLibrary中。
当创建RayTracing Pipline时调用GetRayTracingLibrary()从这个全局数组中取出即可。
TraceRay()的其它参数
除此之外,TraceRay() API还有剩下两个前文未表的参数,即InstanceInclusionMask和RayFlags。
Instance Inclusion Masks
在一个加速结构TLAS中,我们可以为每一个Instance定义一个Mask属性,具有相同Mask属性的Instance可以通过该Mask值提取出来,达成分组的目的。
当我们在TraceTray()调用时传入InstanceInclusionMask值时,只有Mask属性值与这个值进行逻辑与操作后结果不为0的Instance才有可能与该光线进行求交测试,否则将被直接忽略而走不到Intersection那一步。
这相当于在单个加速结构中可以将不同子集的几何体实例表述为一个组,而不是单独将这些分组的实例分别表示为不同的独立的加速结构,这样就可以在Traversal性能和效率之间进行调节。
比如我们可以在进行阴影计算时忽略一些物体,但是进行光照着色时又需要考虑这些物体。
Ray Flags
RayFlags通过指定当前光线的一些标记,从而决定当前光线进行Traversal和Intersection的流程,包括控制求交时的某些特殊规则、强制修改交点处的表面属性(大概率也是用作求交)等。甚至可以决定要不要执行之前五个Shader中的某些Shader,从而给整个RTX流程提供一个更直接的灵活性。。
一个常见的例子是设置RAY_FLAG_FORCE_OPAQUE标记,它将认为在求交时所有的物体都是不透明的,这将导致即使是半透明物体,也不会走到Intersection Shader。
另一个常见的例子是设置RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH标记,它相当于所有的Any Hit Shader都调用了AcceptHitAndEndSearch(),直接退出当前的Traversal循环。
还有一个常见的例子是设置RAY_FLAG_SKIP_CLOSEST_HIT_SHADER标记,它会使所有本该执行的Closest Hit Shader都不执行(当然也不会转去执行Miss Shader)。
一个综合性的例子是,在一些情况下,比如计算阴影或者AO,我们可能只想得出物体与光源的遮挡关系,并不需要着色、也不需要具体交点的数据,即从物体表面出发,投向光源方向的光线,是否和场景没有任何交点。这种情况下我们可以设置RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH标记,让光线在与场景有任何交点的情况下退出Traversal循环,同时设置RAY_FLAG_SKIP_CLOSEST_HIT_SHADER标记,无需要在CHS执行任何额外的操作。而没有被遮挡住的光线才会走进MS,并进行一些计算。
IS 与 AHS
对于前文提到的RTX流程图3-2,我们其实隐藏了Traversal和Intersection的内部细节。虽然前文也介绍了一些IS的ReportHit()和AHS的AcceptHitAndEndSearch()等内部调用,但并没有详细地展开其协作细节,此处将其更清楚地展开一下。
展开后的流程图如下所示。
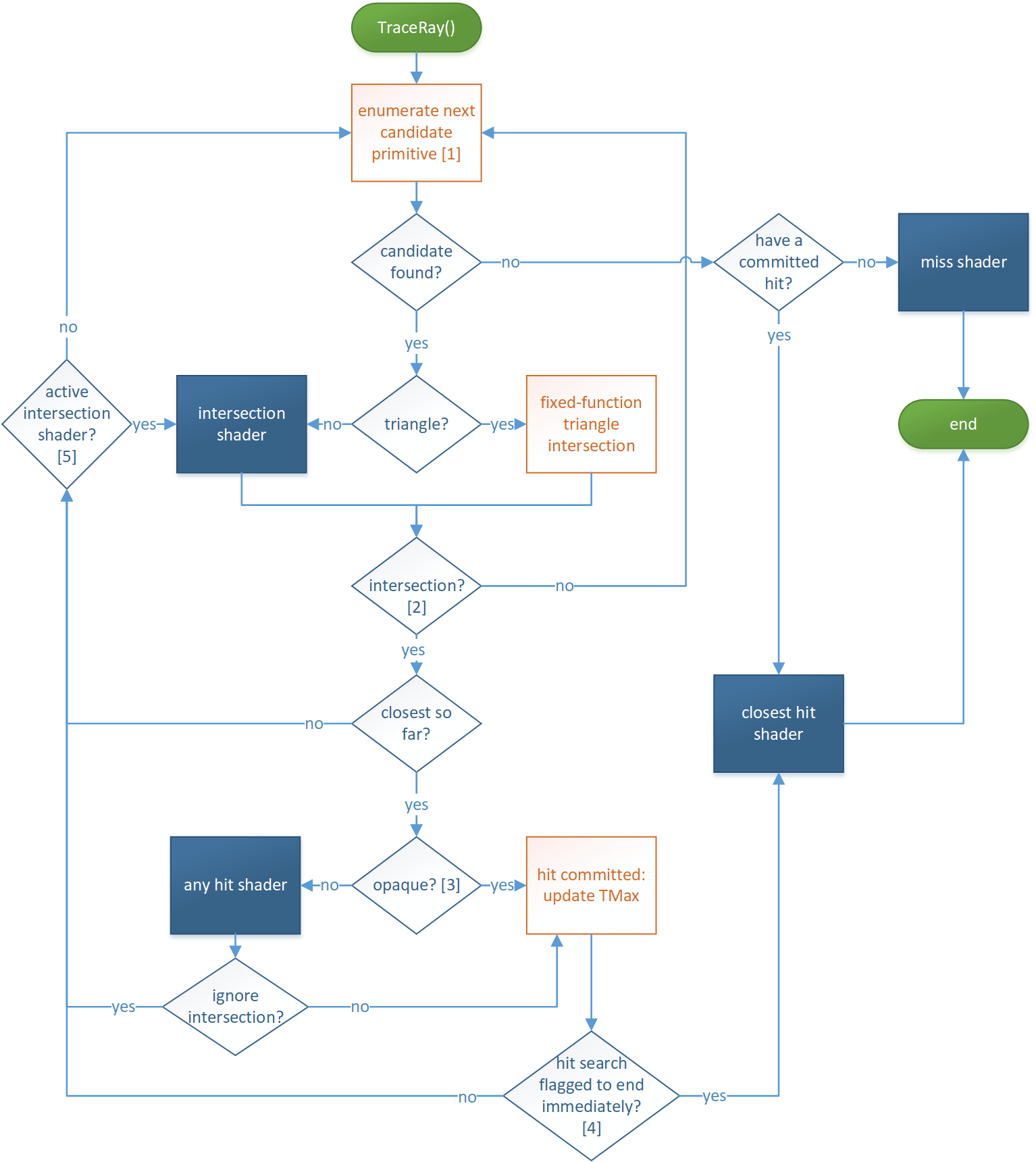
在这之前,我们需要明确一下上报交点(hit committed)操作的具体内涵,它是指更新光线的TMax属性,从而记录迄今为止最近的交点。我们知道,对于一条光线的求交是在其[TMin, TMax]范围内进行的,这里更新了光线的TMax,那也就意味着在这之后的求交范围更窄了,而不是始终在初始的[TMin, TMax]范围内进行求交。
除此之外,IS的ReportHit()是一个异步的,长生命周期的函数,它的调用将会挂起当前IS,被其他操作激活时返回,将根据返回值继续执行IS剩下的代码流程。
我们首先从流程上罗列一下Traversal和Intersection会碰到的各种情况。
- 光线和图元无相交。
IS不会调用到ReportHit(),此后Traversal将进行下一个图元的遍历。- 对应图中
intersection?节点的no分支。
- 光线和图元相交。但此时交点
hitT大于TMax,即找到的交点不是迄今为止最近的。
IS会调用到ReportHit()并挂起。此时将激活IS,ReportHit()返回值为false。- 对应图中
closest so for?节点的no分支。
- 光线和图元相交。但此时交点
hitT小于TMax,即找到的交点是迄今为止最近的。
IS会调用到ReportHit()并挂起。- 此时若物体是不透明的(
opaque),会上报交点。- 此时若未设置
RayFlags标记RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH,- 将激活
IS,ReportHit()返回值为true。- 对应图中
opaque?节点的yes分支和hit search flagged to end immediately?的no分支。
- 光线和图元相交。但此时交点
hitT小于TMax,即找到的交点是迄今为止最近的。
IS会调用到ReportHit()并挂起。- 此时若物体是不透明的(
opaque),会上报交点。- 此时若设置了
RayFlags标记RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH,- 将不会激活
IS,直接退出Traversal循环。- 对应图中
opaque?节点的yes分支和hit search flagged to end immediately?的yes分支。
- 光线和图元相交。但此时交点
hitT小于TMax,即找到的交点是迄今为止最近的。
IS会调用到ReportHit()并挂起。- 此时若物体是半透明的,则执行
AHS。- 此时若
AHS调用了IgnoreHit(),- 则激活
IS,ReportHit()返回值为false。- 对应图中
opaque?节点的no分支和ignore intersection?的yes分支。
- 光线和图元相交。但此时交点
hitT小于TMax,即找到的交点是迄今为止最近的。
IS会调用到ReportHit()并挂起。- 此时若物体是半透明的,则执行
AHS。- 此时若
AHS调用了AcceptHitAndEndSearch(),- 则会上报交点,但将不会激活
IS,直接退出Traversal循环。- 对应图中
opaque?节点的no分支和ignore intersection?的no分支,以及hit search flagged to end immediately?节点的yes分支。
- 光线和图元相交。但此时交点
hitT小于TMax,即找到的交点是迄今为止最近的。
IS会调用到ReportHit()并挂起。- 此时若物体是半透明的,则执行
AHS。- 此时若
AHS既没有调用IgnoreHit(),也没有调用AcceptHitAndEndSearch(),- 则会上报交点,也会激活
IS,ReportHit()返回值为true。- 对应图中
opaque?节点的no分支和ignore intersection?的no分支,以及hit search flagged to end immediately?节点的no分支。
除此之外,即使条件走进了情况g,但RayFlags标记设置了RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH,也会进入情况f。
至此,Traversal和Intersection内部相关的流程便几乎梳理完了。流程图上所有可以执行的流程基本上不外乎上面a ~ g几种情况。尤其需要关注是的e、f、g三种情况,它们是IS和AHS相互配合产生的结果。
我们还可以根据IS的挂起激活情况以及ReportHit()的返回结果重新归纳一下不同的情况,如下所示。
- 没有执行到
ReportHit()。对应上面情况a。
- 执行了
ReportHit()挂起IS,后续激活并返回了false。对应上面情况b、e。
- 执行了
ReportHit()挂起IS,后续激活并返回了true。对应上面情况c、g。
- 执行了
ReportHit()挂起IS,后续并没有被激活。对应上面情况d、f。
更多细节参考微软文档[DirectX Raytracing (DXR) Functional Spec]。
路径追踪
从前文的描述我们可以看到,光线追踪更多地体现在了一种能力上,即光线与场景的求交能力。我们可以利用这个能力做很多事情,如计算GI、Shadow、AO、Reflection等等。整个RTX流程也给我们提供了相当多的可自定义的流程和数据,以及部分可编程的数据处理阶段。
而路径追踪则是光线追踪能力的另外一种应用,而且从一定程度上可以说是最正规的应用。它以取代当前呈现画面所使用的光栅化流程为目的,充分利用这个求交能力来尽可能模拟现实中的光线传递方式。
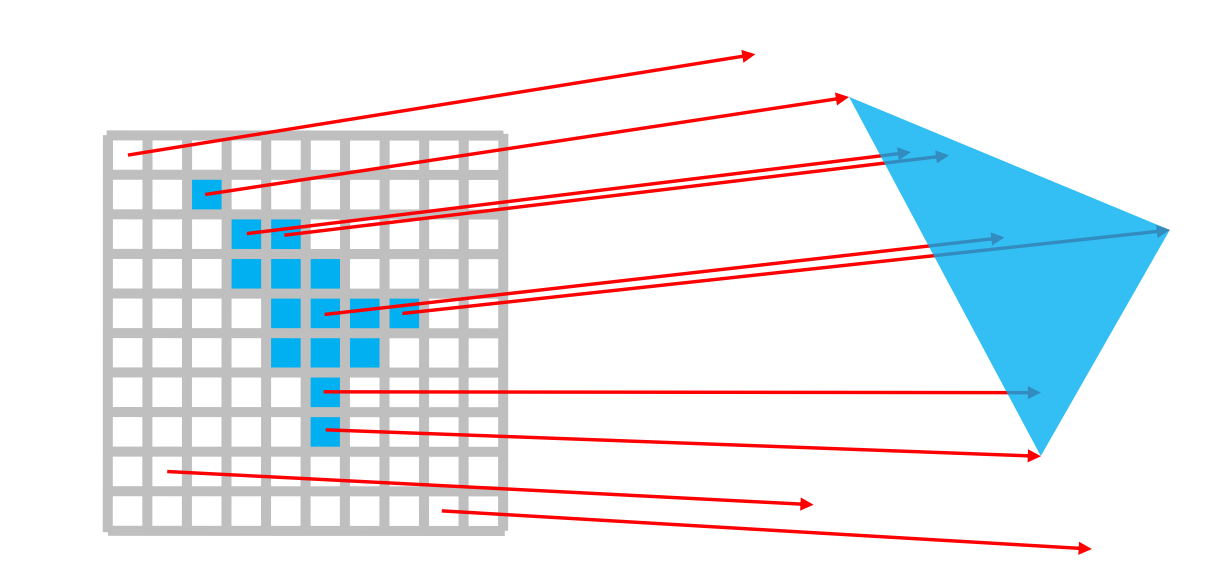
而对于现实光线传递方式的模拟,也有不止一种方法,各种方法决定了光线的数量和方向的决定方式不同,或者说采样方式不同。其中比较经典的有基于RR(Russian Roulette)[11]的方案和基于NEE(next event estimation)[12]的方案。此处暂时不作展开。
ue也给我们提供了丰富的Path Tracing接口。但出于采样性能等限制,它通常无法直接应用于生产环境,而是被用作Ground Truth以评估其他算法的误差等。
后记
个人认为从目前来看,RTX提供了一种很强的光线和场景求交能力,如果再进一步的话,就是提高光线追踪时光线的采样效率和复用率,从而获得更高质量和高性能的表现。事实上,已经有很多方案在这样做了,比如之前提到的ReSTIR GI等,这也是笔者未来一段时间打算研究并整理的一部分知识。
关于RTX的应用除了Path Tracing还有其他途径,如RTX AO,RTX Shadow, RTX Reflection等,后续有时间再展开这一部分内容。
出于关联性和降低理解曲线的目的,本文其实杂糅了全局光照方案简介、RTX光追、DDGI三部分内容,后续会尝试将其分为三篇相互独立的部分并持续地各自扩充完善相关知识。
第二个后记
大抵是在鹅厂写的最后一篇了吧。
回想起2018年的那个春晨,随着最早的一班公交颠簸了半个时辰(武汉的路是真的不好走),晕头转向地来到了华科旁边的面试点,懵懵懂懂进行了人生第一场面试。当时的我恐怕也没有想到,虽然只是一场看起来很是稀松平常的实习面试,却改变了我后面几年的人生轨迹。面试官儒雅的谈吐与随和的性格直接把我忽悠瘸了,当时满脑子想的就是,如果这个能过的话,后面也别秋招了,也别考虑别的了,就这个了。
就这样,实习,转正,入职,一晃眼就在深圳晃了四年。虽然四年生涯被疫情无情地包裹了三年,但我依然觉得自己是幸运的,甚至因为无尽的关照和无限的包容,还能感受到几分幸福。从讯美到科兴,背锅侠也当过,调参侠也干过,最后还进化成了甩锅大侠。
回首在此最大的收获,无疑就是朋友和技术。
那是一群茂腾腾的小伙伴,他们的身后是一堆bug单,他们朴实得就像那堆bug。咝溜溜的pm吹动了处理日期,也吹走了他们的发丝。他们的神情沉稳而安静。紧贴在他们身体一侧的bug,呆呆的,似乎从来不曾复现。但是:看!--一改起来就发狠了,忘情了,没命了!百十个斜背bug的带佬,如百十块被强震不断击起的石头,狂舞在你的面前。这些可爱的石头,有的自律高效,热爱生活,堪为我辈榜样;有的急人所难,事了拂去,可称天使大姐;有的倾盖如故,相见恨晚,竟成吹水狐朋。凡此种种,数不胜数,都汇聚成了值得珍藏一生的财富。
而在技术成长上的道路上,却并不如此“茂腾腾”了。总归也有三分波折,三分运气,一分努力,剩下几分天意如此吧。好在最终也踉踉跄跄踏上了自己最想走的道路吧。虽然这两年在这条理想之路上走的那是一个庸庸碌碌,那是一个潦潦草草,那是一个“三步两回头”,但大概也是前进着的吧。即便没看几篇论文,没写几篇博客,也没推几个公式,但也学会了几个专业术语的英文拼写,实在是莫大的欣慰了。
如今浮云游子,落日故人,虽不舍,此意此情,也大抵如此了。
人生在世,本当轻生死重别离,但人生又处处是相逢,别离的事儿,倒也不必如此挂怀。今当远离,希望大家过去现在和将来,都能挺好的,都能继续茂腾腾。
共勉。
参考
[3]ReSTIR GI: Path Resampling for Real-Time Path Tracing
[4]GI-1.0: A Fast Scalable Two-Level Radiance Caching Scheme for Real-Time Global Illumination
[5]Efficient Light Probes for Real-time Global Illumination
[8]Intersection attributes structure
[9]DirectX Raytracing (DXR) Functional Spec