【cg】常见的空间加速结构
前言
本文开始介绍一些常见的空间加速结构,这些加速结构可能会被广泛地应用于各个开发场景,在渲染、光线追踪等情境下尤甚。本文是一个开始,只入门性质地介绍一些浅显的理论和精简的实现。
常见的空间加速结构
八叉树(Octree)是一种耳熟能详的数据结构,它本质上二叉树(Binarytree)及四叉树(Quadtree)没什么区别。只不过在树的规模,划分的维度上有些区别,但划分的方法都是绝对公平的均匀划分。
四叉树会均匀地将平面划分为四等份,然后继续递归划分。
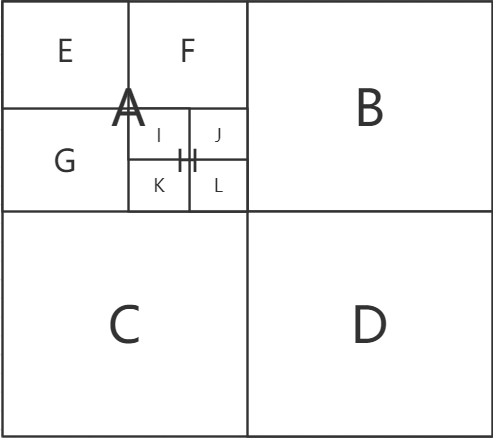
八叉树会均匀地将空间划分为八等份,然后继续递归划分。所以八叉树的节点是基于空间的,代表着场景空间中的一块区域。
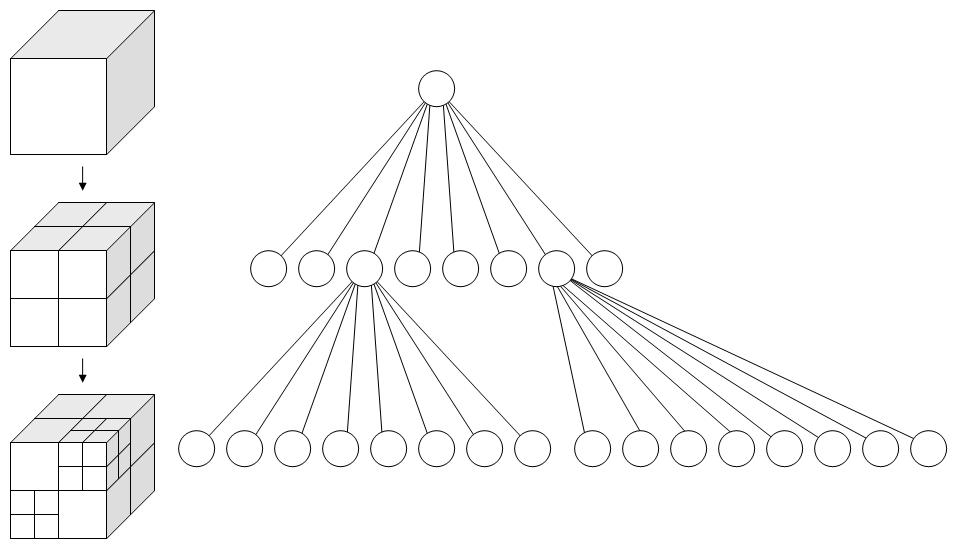
八叉树的实现相当简单,会写二叉树的同学十六叉树应该也是信手拈来。关于其在工程上的实现后文会提到。而其在算法上的实现,这里可以参考一道古老的关于四叉树的算法题稍作了解。

1 | char s1[maxn], s2[maxn]; |
从实现上看一般分为两个步骤,建树和查询。其中建树过程会递归地划分场景空间直到达到最小粒度。而查询则是普通树的深搜或者广搜。
对于动态变化的场景,我们可能还会额外添加物体进入和离开某个八叉树节点的条件,比如离开时需要远离到更大的距离才算离开,防止某物体在两个节点间反复横跳。这种八叉树又被叫做是松散的。
八叉树可以应用于场景管理,特别是地广人稀的室外空间的管理。还会被用在光线追踪、物理碰撞检测等方面。
bvh树又称层次包围盒(bounding volume hierarchy based on tree)。
bvh树是一个二叉树,每个节点最多只有两个子节点。
bvh树的节点与八叉树不同,它并不是基于空间的,而是基于场景中物体的图元的,更准确的说,是基于图元的包围盒的。它首先需要将场景中所有的物体的图元(物体本身、物体的一部分或三角形面片等各个粒度都可)的包围盒(AABB包围盒或球形包围盒都可)作为输入。

bvh树的建树过程也是一个递归的过程。它需要将场景中所有的图元加到根结点上,然后从根节点递归地进行划分,直到某节点的图元数量为1或者达到最小粒度终止。
其一次划分的结果是给当前被划分的节点生成了左右两个子节点,子节点的内容是其包含的图元列表。然后再分别用同样的方式划分左右两个子节点。划分一个节点的过程大致如下。
1.首先遍历当前节点的所有图元,构建一个最小的包含所有图元的中心点的包围盒,并求出这个包围盒最长的那个轴。
2.延该轴进行划分,划分的方法有很多种,这里介绍一下其中比较经典的一种
SAH(surface area heuristic)。

如上图所示。这种方法首先把场景按该轴的方向划分成多个同等宽度的桶bucket。
然后遍历当前节点的所有图元,将它们放到它们的中心点所性的bucket里,并更新bucket的包围盒大小。至此生成完备的bucket数据。
然后遍历每一个bucket,求如果以这个bucket作为分界线划分右左右两个子节点会产生多少消耗。从中选取消耗最小的bucket作为划分的边界。将该bucket左边的所有bucket里的图元放到左子节点里,右边的放到右子节点里。
而消耗的计算,则使用以下公式。
\[ c(A, B) = t_{trav} + P_A \sum^{N_A}_{i=1} t_{isect}(a_i) + P_B \sum^{N_B}_{i=1} t_{isect}(b_i) \tag{3.1} \]
其中\(t_{trav}\)和\(t_{isect}\)是两个可配置的与光线追踪有关的系数,这里可以认为是常数。\(P_A、P_B\)分别是两边包围盒的大小占该节点总包围盒大小的面积比例。\(N_A、N_B\)分别是两边所拥有的图元数量。
上述公式转换成求每个bucket的消耗的代码如下。
1 | <<Compute costs for splitting after each bucket>>= |
3.对划分出来的左右子节点同样进行步骤1、2,直到图元数量为1或者达到最小粒度终止。
以上过程可参考pbrt 4.3 Bounding Volume Hierarchies
在pbrt里介绍了很多种划分方法,上面只是其中一种SAL。
1 | <<BVHAccel Public Types>>= |
可以看出,正因为bvh树的节点是基于图元而非基于空间的,所以它具有更灵活的粒度来分割物体,比八叉树更适合用于光线追踪,划分效率更高。
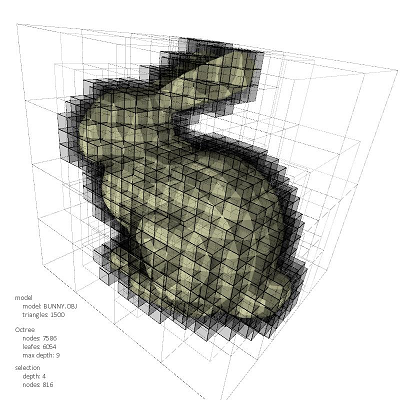
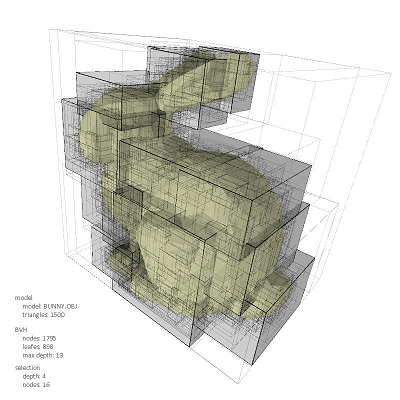
我们也可以选择不同类型的包围盒参与bvh树的划分,如AABB包围盒可以生成AABB层次包围盒树,或者最简单的球体包围盒生成球体树,都有其异同和优缺点。
k-d树(k-dimensional tree)也是一个二叉树,每个节点也是最多只有左右两个子节点。
k-d树的节点也不是基于空间的,也是和物体相关的,但它并非是真正服务于物体的,而是真正服务于坐标点的。我们会将场景中所有物体的中心坐标点作为数据输入来建树。
k-d树的建树过程也是递归的。首先需要将所有的坐标点作为输入数据加到根节点上,其递归过程大致如下。
1.对于当前节点的所有坐标点,选择一个方差最大的维度作为其主维度开始进行划分。
2.在主维度上,选定中值所在的坐标点作为当前节点的主坐标点,经过该坐标点并与主维度垂直可确定一个唯一的平面,这个平面称作超平面,每个节点其实代表着一个超平面。
3.在主维度上小于中值的坐标点放在左节点上,大于的放在右节点上,生成当前节点两个子节点。
4.对各个子节点,重复步骤1、2、3直到不可继续划分或达到划分粒度。
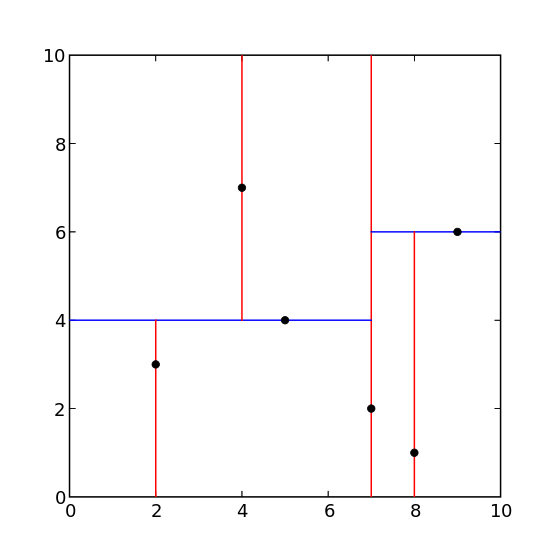
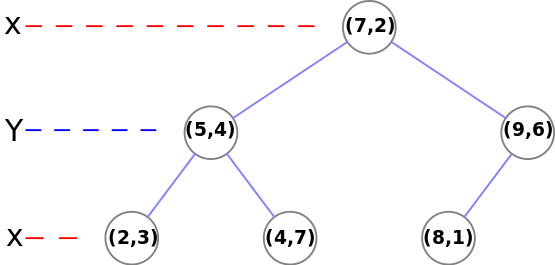
k-d树其实在每个维度上都是一个相对严格的二叉树,只不过各个维度的数据交错起来了。在一个维度上生成二叉树的时间复杂度是O(nlogn),所以k-d树的建树时间复杂度为\(O(k \cdot nlogn)\)。
k-d树的查询是极快的O(logn),因为对于每一个节点来说,都只需要比较它的某一个维度的数据。所以它经常被用作给定坐标点的最近邻查询,即查询与给定坐标点最接近的k个点及其最近距离。即使是进行区间查询,k-d树的时间复杂度也可以达到\(O(k \cdot n^{1-\frac{1}{k}})\)。
其在算法上的实现也可以参考一道老题。
1 | struct Point |
像这种以超平面为节点的二叉空间分割树,有一个更一般的数据结构叫做bsp树(binary space partitioning tree),其每个节点的超平面可以是任意超平面。

所以k-d树实际上是一种特殊的bsp树,它是超平面只与坐标轴平行的bsp树。
由于可以是任意超平面,所以bsp树的构建比k-d树要更复杂些,主要原因是判断该超平面与物体的关系时的情况有些复杂,无法像k-d树那样只通过一个维度的数据就可判断,而且还有可能出现同一个物体有一部分在超平面前,有一部分在超平面后的情况,此时则需要进一步分割物体,使其一部分添加在前方的节点里,一部分添加在后方的结点里。
可以发现,上述三者一个最明显的区别就是节点内容。
八叉树的节点内容是空间的区域以及该区域内的物体列表。
bvh树的节点内容是场景中的划分到该节点的图元(及其包围盒)列表。
k-d树的节点内容是三维的空间坐标点,以及当前深度的维度,从而确定一个当前节点所代表的超平面。
上面是各加速结构在算法上的原理及实现,但在工程上的实现却又不完全是那么回事,下面以unreal中的八叉树实现来体会一下。
unreal中的八叉树实现
八叉树(Octree)在ue4中工程化的实现方式的大部分代码位于Engine\Source\Runtime\Engine\Public下的GenericOctree.h和GenericOctree.inl。
1 |
|
这是一个模板类。其模板参数ElementType是每个节点的真正内容。OctreeSemantics是模板的辅助语义,它使得使用者在该类中某些固定的流程结构中定制特定的步骤或数据,这在设计模式中称为模板方法模式(Template Method)。
以ue4场景中的物体为例,它使用了以下类型作为模板参数来达到定制化的八叉树。
1 | typedef TOctree<class FPrimitiveSceneInfoCompact,struct FPrimitiveOctreeSemantics> FScenePrimitiveOctree; |
建树参数
1 | template<typename ElementType,typename OctreeSemantics> |
构建一个八叉树需要以下参数。
Origin -- 树的原点。
Extent -- 树的范围(最大的包围盒)。
LoosenessDenominator -- 松散度分母,用于计算同级节点重合部分。由此也可以看出unreal实现的八叉树其实是一个松散八叉树。
MaxNodeDepth -- 最大的节点深度。
建树流程
unreal中的建树流程,即添加一个物体到八叉树中的流程,如下所示。
1.以根节点作为当前Node,开始使用迭代器遍历node。
这里的迭代器实现了一种深度优先遍历,它维护了一个以节点索引为元素的栈。
对于当前的节点,调用TConstIterator::PushChild()将其子元素压入栈顶。并调用TConstIterator::Advance()进行迭代,每次迭代将栈顶元素出栈。
2.如果当前节点非最终的叶子节点或者当前节点拥有的元素过多,则尝试创建其子节点。
创建子结点的规则是,如果某个子节点完全包含物体,则将该子节点压入迭代器,等下次迭代便可处理该子节点。
如果当前节点并没有子节点可以完全包含物体,则直接将该物体放入当前节点中。
3.如果当前节点为最小粒度的叶节点,则直接将物体放入其中。
1 | template<typename ElementType,typename OctreeSemantics> |
后记
本文所阐述的空间加速结构只是一个初步的概念认识和简单实现,后续会继续更新一些使用细节和扩展,以及更高科技一些的使用方式,如在GPU上并行建树等具有实际价值的方法。但无论如何,掌握理论总是首要的。
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=3i6tlz41tbi8s